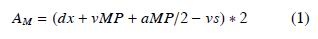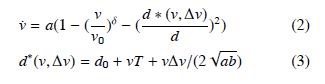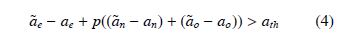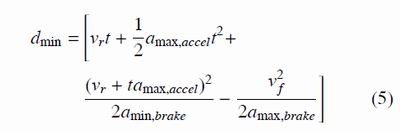王飛躍等:代理技術Agent 在智能車輛與駕駛中的應用現狀
發布時間:2020-04-22 14:12:58
從智能體的角度出發,對智能車輛作為單智能體系統的研究進行介紹和總結;針對智能網聯汽車中多智能體系統在典型場景下控制問題的研究進展進行了分析與闡述;介紹了“車端感知,遠端管控”的平行駕駛技術是未來智能車的發展趨勢,并且闡述了Intel的RSS模型從法律角度對智能汽車決策的規范。最后,對基于多智能體系統的智能汽車控制策略進行了展望。
摘要:從智能體的角度出發,對智能車輛作為單智能體系統的研究進行介紹和總結;針對智能網聯汽車中多智能體系統在典型場景下控制問題的研究進展進行了分析與闡述;介紹了“車端感知,遠端管控”的平行駕駛技術是未來智能車的發展趨勢,并且闡述了Intel的RSS模型從法律角度對智能汽車決策的規范。最后,對基于多智能體系統的智能汽車控制策略進行了展望。
關鍵詞:智能汽車;智能體;多智能體系統;平行駕駛;RSS模型
智能傳感、大數據、云計算及物聯網等人工智能關鍵技術近幾年的飛速發展,極大推動了智能汽車這一集感知–規劃–決策–執行功能于一體的復雜智能系統的進步。智能汽車的出現將極大地改善交通狀況、降低環境污染、減少交通負荷、保證交通安全,從而更好地推動社會發展。
智能體(Agent),又稱代理系統,是在20世紀80年代中期興起的屬于分布式人工智能的一個概念,從20世紀80年代起,智能體和多智能體系統經歷了快速的發展。智能體成為一個成熟的、有前途的研究和應用領域,它匯集并借鑒了許多學科的成果、概念和思想,包括人工智能、計算機科學、社會學、經濟學、組織和管理科學和哲學。智能體系統的成功使得分布式人工智能(DistributedArtificialIntelligent,DAI)有了更加現代化的定義:多智能體系統的研究、構建和應用;也就是說,多個追求一定目標或者完成一些任務的相互交互、智能的智能體構成的系統。基于智能體的方法由于在地理分布上的特性和周期性的忙閑操作的特點,非常適合用于交通和運輸管理系統。值得注意的是,空中交通控制和沖突管理系統是智能體技術最先應用的幾個領域,并且相關研究依然很火熱。分布式交通監控任務(DVMT)是智能體研究和分布式人工智能歷史上另一個早期的里程碑。Lesser和Corkill針對地理上不同分布的智能體之間數據和目標的通信,提出了“黑板”的概念。每個智能體可以感知被監控區域的一部分。然而,隨著現代控制尤其是分級控制的興起,城市交通管理問題的解決方案、基于功能分解的傳統控制方法在理論研究和實際應用中越來越盛行。目前大部分的研究工作集中在發展分級結構、分析建模、優化算法等在實時交通中有效地應用,比如CRONOS,OPAC,SCOOT,SCAT,PRODYN,RHODES等交通控制系統。
未來的智能交通系統(IntelligentTrafficSystems,ITS)應當全部由智能化、自主化的智能體系統構成。這些智能體運行在交通控制中心、道路交叉口、高速、街道等之間,通過因特網、無線網和自組織網在合適的時間獲取準確的信息并且作出最正確的決策,使交通系統最終實現智能。
近些年來,越來越多的研究將基于智能體的方法應用到智能車的問題中去。例如自動泊車、運輸規劃、分布式控制和交通仿真等。盡管這些都是交通系統中的重要問題,但是并沒有系統地解決智能交通系統的核心問題。網聯智能汽車利用(VehicletoEverything)V2X技術實現車輛和其他智能體之間的信息交互,將汽車從傳統的孤立駕駛環境下解放出來,能夠有效降低交通事故、緩解交通堵塞以及提高交通出行效率。使用BDI模型將智能汽車建模為具有信念(Belief)、愿望(Desire)和意圖(Intention)的智能體,信念為Agent對世界的認知,包含描述環境的數據和描述自身功能的數據,例如周圍智能車的運動狀態、道路狀況、交通信號以及智能車本身的導航、速度等,是Agent思維活動的基礎;愿望是Agent對環境狀態的一種期待和判斷,車輛需要基于信念信息判斷當前加減速、是否并線、保持安全等;意圖是Agent要達到的目標,對于當前動作具有指導作用。傳統的控制系統被分解為多個任務取向的Agent,能夠在處理效率以及能耗等方面得到極大的優化,這對于追求安全、高效的智能車技術具有非常重要的意義。
本文第1部分從智能體的基本特性出發,首先介紹了智能汽車本身作為由感知層、管理層和決策層等多個智能體模塊構成的整體,分析各智能體模塊之間協同與合作,構成可進化、發展的自主駕駛學習系統。接下來,第2部分介紹網聯智能汽車中Agent技術的應用,對網聯智能汽車場景下,車輛作為Agent在車輛換道、交叉路口以及車輛編隊等典型場景下的控制策略進行了概述。第3部分則總結了基于Agent的智能汽車仿真系統框架。第4部分介紹了基于Agent的平行駕駛是智能汽車安全上路的安全高效智能途徑以及RSS模型如何從法律角度規范智能汽車Agent的行為。最后進行了總結,并對未來智能體技術在智能汽車中的應用進行了展望。
1 基于多Agent的智能車架構
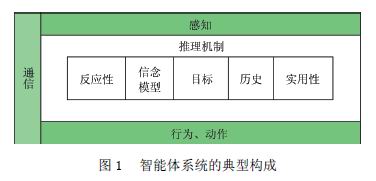
對于智能體Agent最為廣泛接受的定義來自于Russell和Norvig的擁有感知周圍環境并通過執行器進行操作能力的靈活且自主的實體,圖1給出了智能體系統構成。
與一般簡單控制器相比,智能體的特性如下:
(1)情境性:智能體可以通過傳感器和執行器與周圍環境進行交互,智能體所有輸入都是其與環境交互的直接結果。這一點使其與專家系統不同。
(2)自治性:智能體能夠獨立自主地選擇自己的行為,而不受人為干預以及網絡中其他智能體的影響。該屬性保證智能體內部狀態不受外界干擾的影響,尤其是外部擾動而導致的不穩定性。
(3)推理性:智能體可以基于觀察而推理得到概括信息的抽象目標特性的能力,這可以通過利用可供使用的相關內容實現。
(4)響應性:智能體能夠感知環境的狀況,并且針對環境的變化作出及時響應的能力,這一點在一些實時性要求很高的應用中尤為重要。
(5)積極性:智能體具備一定的機會主義特性,能夠根據目標需要主動對環境中的變化作出反應,尤其是動態變化的環境。
(6)社會性:盡管智能體可以不受到外界環境變化的影響,但是它需要在實現目標的過程中與外界環境進行交互。同時應該通過分享經驗的過程幫助其他智能體完成目標。
智能車從任務類型上可被看作為由感知、規劃和決策多個智能體組成的異構智能體混合系統。智能系統的智能性體現在可以通過學習得到知識和技能,并將此應用于提高性能上。
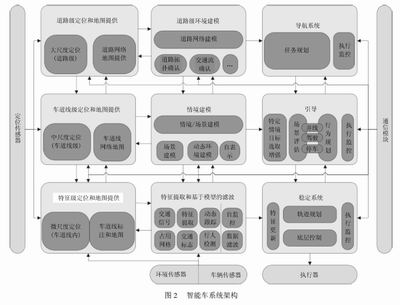
智能駕駛汽車利用激光雷達、毫米波雷達、攝像頭以及GPS等傳感器組成的感知系統,如圖2所示,實時采集周圍環境的數據完成識別紅綠燈、檢測車道線、障礙物,以及行人等一系列行為完成感知的任務,感知得到的信息經過車載中央處理器處理后,對智能車下一步換道、剎車等動作進行決策,在聯網環境下可以與其他車輛、云端和路基設備進行通信,實現感知和運行信息共享任務。
整個過程涉及多個任務的并行處理、計算資源的分配和信息交互等,如何保證實時準確地得到理想的結果,保證智能車安全平穩的運行是目前研究的熱點。基于智能體的智能車控制是解決這個問題的一個有效方案。
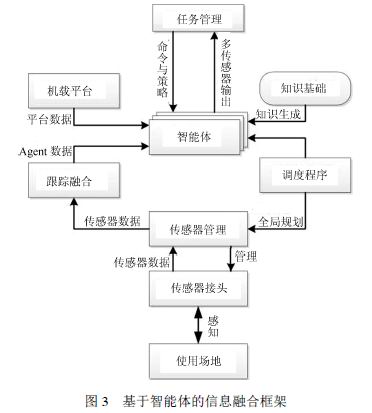
傳感器系統是智能車感知環境的基礎,多樣性的傳感器保證了信息獲取的全面性,但是多傳感器系統的數據融合和資源管理的復雜性問題也應運而生。將智能體技術引入多傳感器系統可以有效解決這個問題。在多傳感器系統中智能體不僅僅起管理作用,智能體獲取傳感器的數據,并為傳感器在傳感范圍、資源分配和執行時間上做規劃。
一種基于信息融合的多智能體智能車輛導航系統,將導航任務分為可協調式和反應式,智能體間完成信息交互、協調運作,結合圖像處理、信息融合的方法實現多傳感器信息融合,達到避障導航的效果。此外,當前智能車各功能模塊的任務處理比較復雜,因此,可以將多個任務分配給多個相互協作的智能體執行,如圖3所示。
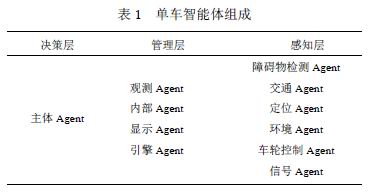
基于多Agent的智能車可以對可能導致沖突的環境參數進行建模減少交通事故,例如根據車輛模型、重量、狀態和天氣因素等參數計算安全的跟車距離。此外,多Agent系統可以重復對多個處理器執行并行計算,使得智能車的各個模塊實時通信,提高決策效果。多Agent技術可應用于單個智能車系統中去。系統架構由決策層、管理層和傳感層組成,每層又由若干可相互通信的智能體構成。不同智能體之間的并行通信保證了它們任務的同步性,從而達到減少執行時間的目的。系統架構如表1。
該系統采用一種中心化的控制架構,主體Agent擁有最高控制權限,使用強化學習提高決策能力,感知層的Agent權限最低,負責向高層提供感知信息,高層可以向底層下達控制命令。
2 網聯智能車Agent控制
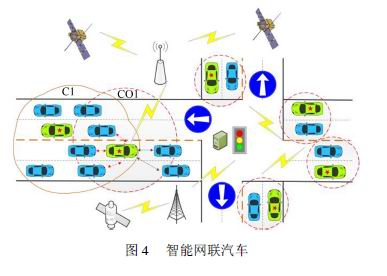
當前的智能車研究主要集中于單車系統在感知、規劃和決策等模塊的研究,車輛各自執行自己的檢測、避障、識別標志等任務,每臺車采集到的數據相互之間也是不共享的,這就要求單車本身各功能模塊非常可靠。而智能網聯汽車的誕生將極大提高單車效率。智能網聯汽車是指搭載先進的車載傳感器、控制器、執行器等裝置,并融合現代通信與網絡技術,實現人–車–路–云端等信息交換、共享,具備復雜環境感知、智能決策、協同控制等功能的新一代汽車,典型架構如圖4所示。
智能汽車與通信技術的結合促進了協同感知和協同操作技術的發展,協同感知允許多個智能汽車相互之間共享感知信息,協同操作使得車輛執行器間的協調得以實現。這些特點保證了智能汽車之間協作性的可能,從而提高了整體的行駛品質和行駛安全。
下文將從換道場景、交叉路口以及車輛編隊等典型場景介紹對智能車Agent的控制策略。
2.1 換道場景
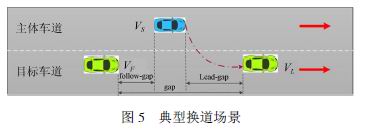
智能汽車在復雜環境下尤其是非結構化道路條件下的決策能力是衡量其智能化的標準。在任何交通模型和仿真系統中,換道場景都是非常重要的研究點,在換道問題的研究中,必須要考慮車輛間信息的交互,智能汽車如何基于對周圍車輛行駛意圖的預測,以及環境的變化并結合自身動態信息及時、有效、安全地作出決策是換道場景問題研究的重點。換道場景可以分為自由換道、強制換道和協作式換道3個場景,如圖5所示。自由換道場景下,待換道車輛Agent不需要與周圍車輛Agent進行交互,可根據與周圍車輛Agent之間的安全距離選擇換道時機;強制換道為待換道車輛Agent以強制周圍車輛Agent減速形成安全距離的方式進行換道,而協作式換道則基于待換道車輛Agent與周圍車輛Agent進行信息交互,周圍車輛Agent主動調整自身駕駛策略保證待換道車輛Agent安全換道。模型對待換道車輛Agent的換道條件作了限制。換道并線的點稱為MP(MergePoint),到達并線點MP的加速度為AM(MergeAcceleration)。
其中,dx為當前位置到達MP點的距離,vMP和aMP分別為車輛在MP點處的速度與加速度,vs為待換道車輛Agent的速度。當車輛到達換道點,基于車輛間距離(gap)、車輛間相對速度以及限定AM決定是否適合換道。
兩種常用的控制速度和決定何時換道的模型是建模汽車縱向動態特性的智能駕駛員模型(Intelli-gentDrivingModel,IDM)和基于換道最小化剎車次數MOBIL決定何時換道的模型。
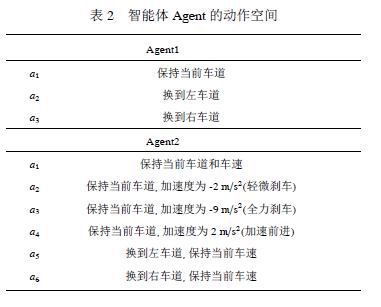
控制車速和換道可看成是強化學習問題,在IDM和MOBIL模型基礎上提出一種深度學習與Q學習相結合的深度Q-網絡DQN智能體來學習Q函數,根據已知的周圍車輛的狀態和可用的道路信息,智能體在其動作空間選擇最佳的換道、加速和減速的動作,智能體的動作空間定義如表2。
如表2所示,Agent1僅僅控制著換道決策,其速度則由IDM模型自動地控制著:
Agent2則在使用IDM模型控制速度并估計周圍車輛Agent速度的基礎上,使用MOBIL模型進行換道決策,決策條件為:
其中,ae,an,ao分別代表當前車輛的加速度、目標車道后續車輛的加速度、當前車道后續車輛的加速度。
WANG等利用長短時記憶(LongShort-TermMemory,LSTM)網絡建模交互環境,將包含歷史駕駛信息的內部狀態傳到深度Q網絡DQN中,在深度強化學習架構下,交互環境長期影響的累計收益可以用來決定最好的控制策略,這可用于智能車在復雜的交叉路口的駕駛和執行換道。人類駕駛汽車經常可以依靠對周圍交通狀況的觀察和感覺輕松地在高速公路完成換道超車,但很多時候突然出現的加塞和變道會增加行車過程中發生事故的幾率,影響其他駕駛員的正常駕駛。而對于智能汽車來說,換道這些動作都需要決策系統完成,因此,智能車需要作出安全、和諧的決策。
當出現需要超車時,智能車首先在行駛過程中需要不斷對周圍車輛的行為進行預測,然后在與他車協作換道或者保持自己行車狀態之間博弈,BMW公司將預測算法加入到決策過程中去,先使用多項式回歸分類器進行實時預測,然后在動作空間選擇對應的避讓或不避讓策略,最終實現基于他車不確定因素的協作行為的博弈。
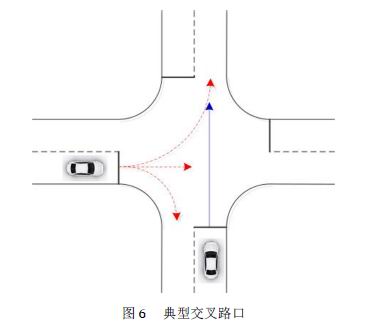
2.2 交叉路口
城市中的交叉路口一般是擁堵最為嚴重的區域,過去也嘗試過很多方法來解決交叉路口的擁堵問題。例如對交叉路口的交通信號燈進行優化控制、將路口的狀況發送給司機讓其提前改道、車輛按照先進先出的順序排序等,這些都是靜態的處理方法,效果不是非常理想。
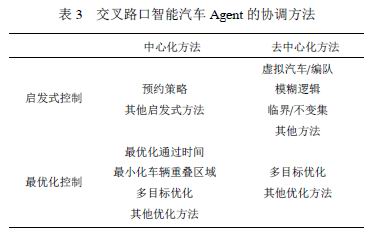
交叉路口智能汽車Agent之間的協調策略一般分為中心化和去中心化兩種方法如表3所示:
去中心化的多智能體系統因為其分布式、可交互特性可應用在交叉路口的無人駕駛車輛的協調上,將車輛與交叉路口智能體網聯起來,車輛智能體之間進行信息交互、協調運行。ROOZEMOND提出一種基于智能體的城市交叉路口控制系統,及時反應交通環境的變化,并基于內部狀態調整自己的決策。該系統包含多個交叉路口交通信號智能體(ITSAs)、道路分割智能體(RSAs)和一些管理智能體。ITSAs在RSAs幫助下管理交叉路口的控制信號,管理智能體控制和協調ITSAs得到全局最優的結果。Choy則給出了分層多智能體系統,最底層為交叉路口控制器智能體(ICAs),中間層為空間控制器智能體(ZCAs),最高層為區域控制器智能體(RCAs)。智能體基于神經網絡和模糊控制技術進行決策,來適應動態變化的環境。
交通信號控制系統在物理位置和控制邏輯上分散于動態變化的交通網絡,將每個路口的交通信號控制器看作為異構的智能體,非常適合采用無模型、自學習、數據驅動的多智能體強化學習方法建模。強化學習智能體與被控對象在閉環系統中不斷進行交互,通過觀察交通環境的實時狀態提取信號控制所需要的交通狀態信息和反饋獎勵信息,以累計回報收益最大為目標選取最優控制策略。作為一種無模型、自學習的迭代性數據驅動方法,多智能體強化學習(Multiagentreinforcementlearning,MARL)為實現閉環反饋的自適應控制提供了一種內涵式的解決方法。在交通信號控制領域,從控制理論來看,MARL控制可根據控制效果的反饋信息自主學習并優化策略知識,是一種閉環反饋控制;根據智能體間交通狀態和信號動作的協調水平,交通網絡MARL控制可以分為3類:完全獨立的多智能體強化學習控制、部分狀態合作的多智能體強化學習控制和動作聯動的多智能體強化學習控制。從系統可拓展性來看,分散式MARL控制具有統一的結構模型,可針對特定路網結構和交通流特性進行相應的改造。從控制實時性來看,它沒有復雜的模型優化模塊,可實時響應時變交通流的變化。
在不考慮所有交通參與者之間交互的情況下,傳統的基于知識的方法假設周圍車輛的狀態和意圖是己知的,而基于規劃的方法則是假設Agent可以依據其反應性和快速重規劃行為保持速度恒定,但這往往得到的都是次優結果。與此相反的一種考慮交互性的方法是部分可見的馬爾科夫過程(POMDP)。該方法將智能車Agent周圍車輛的路徑視為部分可見變量,使用一個運動交互模型模擬車輛之間的交互、一個隨機觀測模型得到周圍車輛未來潛在的測量參數,從而優化智能車Agent在未來場景中的規劃。它們的框架具有以下幾個特點:
(1)適用于任何幾何結構的交叉路口和可變數量的交通參與者;
(2)考慮當前狀態、可以預測其他交通參與者未來意圖的不確定性并且不依賴于V2V通信;
(3)在連續狀態空間操作、可在線調節。
2.3 車輛編隊
智能網聯汽車的一個重要應用場景就是編隊車輛。隊伍中的每臺車可以建模為具有感知、自組織和決策能力的智能體,多個車輛使用(Vehicle-to-Vehicle,V2V)設備進行通信。相同車道的車輛可以保持較小的車間距離,增加道路容量和行駛安全、減少交通擁堵發生、增加燃油經濟性。
作為智能網聯汽車中關鍵技術的無線傳感器網絡(WirelessSensorNetwork,WSN)是網聯的基礎,安裝在車上、道路的傳感器網絡是感知模塊的核心。路基傳感器網絡可以對車流量、該區域的車輛運動信息等進行監控,還可以用于對特定車輛或者目標進行跟蹤。基于WSN的目標跟蹤算法大致可分為兩類:非預測跟蹤和預測跟蹤。
WSN作為一種分布式系統,節點擁有獨立解決問題的能力,具有自治特性,與多智能體系統非常相似,當單個智能體由于缺乏信息、知識、能力、資源而無法獨立完成任務時,多智能體的協作可以很好地解決問題。因此,可以將傳感器節點看作智能體,將多智能體技術應用到傳感器網絡的協同目標跟蹤應用中。感知智能體(SA)、管理智能體(MA)以及警告智能體(AA)形成動態的聯盟,在跟蹤環節,當跟蹤目標出現時,AA智能體發出信號,SA智能體進行動態跟蹤、進行本地決策,將監測數據和狀態信息發送給MA智能體。整個跟蹤過程中3種智能體的狀態不斷變化,傳感器網絡中的被激活智能體也隨著被跟蹤物體位置變化而變化,即聯盟及成員處在不斷新生和解除的動態過程中。在聯盟內SA智能體與MA智能體的數據,采用貝葉斯估計的方法進行協同信息處理,傳感器網絡中智能體間的信息交流保證了新的管理智能體MA以最高效的方式產生。
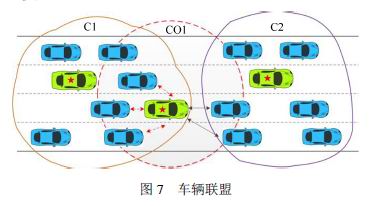
車輛編隊通常包含一個主導車輛和一隊跟隨車輛,然而一個顯著問題就是編隊中會時刻有車輛加入和離開,處理好這種動態變化的環境就變得非常重要。
去中心化的動態網聯車聯盟結構生成算法cvCSG將車輛集合分解為相互不兼容的聯盟,每個聯盟有一個主導,主導利用與成員的通信確定聯盟的組合方式是否有益,并且決定其成員何時離開和新成員的加入。算法使用場景特點如下:
(1)交通系統沒有中心處理節點,主導者只對自己聯盟有控制效應;
(2)沒有具有全局知識的中心節點,所有主導及其成員通過V2V通信獲得他們所需要的周圍信息;
(3)通信以單段或多段路徑規劃方式實現。
交通環境是動態變化的,網絡拓撲結構持續變化并且這些變化事先未知。
使用編隊算法僅僅需要臨近車輛的動態信息,因此,也適用于大的編隊場景且容易在有車輛加入和離開時收斂到理想的隊形。一種集群環境下的信息–物理車輛編隊控制算法,利用移動智能體自組織網絡的協調整體特性,將智能車的集體行為建模為多目標的匯聚運動(Multi-ObjectiveFlocking),不同于車輛固定隊型編隊運行,匯聚運動容許車輛隨時加入或者離開編隊,這就使得車隊在遇到障礙物和前方變窄道路時變得更加靈活。其靈活性還體現在車隊中的智能車Agent不必擁有相同的目的地,隊形也不必像固定編隊Platoon那樣不可變通。當多個Agent滿足只與其所屬環境鄰域的智能體交流,并且在一定時間區間內具有凝聚、自組織和自調整能力時可以被視為具有匯聚行為。基于匯聚行為的理論基礎,分別研究了:
(1)彎道、直線、糾纏態等道路行駛環境下智能車Agent防碰撞;
(2)多車道情況下的換道;
(3)緊急情況下的剎車控制;
(4)轉彎和防止碰撞行人。
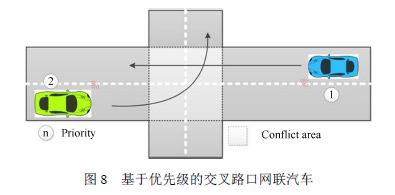
網聯環境下的智能車由于具有V2V通信和V2X通信能力,可以在智能體系統的協調下根據當前交通動態來規劃自己的路徑,并且與別的車輛共享自己的部分導航信息,如圖8所示。這種交互協作可以在沒有紅綠燈的情況下,保證交叉路口車輛順利通行而不會發生擁堵,車輛根據交叉路口智能體分配的權限按照先進先出的原則通過。
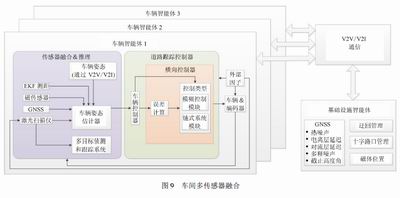
在一般的網聯智能汽車研究中,智能汽車Agent主要利用自身的感知模塊對環境信息進行感知,V2X模塊則用于與周圍可通信設備交互,獲取額外的信息。這種模式對于智能汽車Agent的要求較高。DE等提出一種基于Agent的學習框架,以路邊的基礎設施為主體,對道路環境進行監控,基于交通環境為進入該區域的智能汽車Agent做最合理的規劃。網聯智能車被建模成理性智能體,基于(VehicletoInfras-tructure,V2I)的通信架構利用深度模仿學習實現道路基礎設施主導的策略學習。可動態決策的Agent的運動被仿真為在有恒定速度障礙物環境下的走迷宮,配合車間多傳感器信息融合,如圖9所示,利用強化學習為智能汽車Agent的具體行為作決策。
2.4 基于Agent的智能車仿真
車流量增多和車禍、并線引起的車速降低是導致高速公路擁堵的主要原因。為了研究車流量預測方法和交通擁堵緩解策略,交通仿真可以模擬出現實中難以重現的交通狀況。多智能體系統非常適合用來建模和仿真交通系統,因為它提供了一種直觀的方式來描述每個層級的智能實體。在多智能體交通仿真系統中,每個智能實體被建模為一個智能體,智能體可以以競爭和合作的方式與別的智能體共存。之前有一些利用遺傳算法和元胞自動機的交通仿真研究,但是缺少預測最佳擁堵緩解策略的高效算法。
強化學習中的深度Q學習可以在復雜環境下確定最佳策略。在自動駕駛環境下交通環境的仿真中,仿真環境將每輛車作為一個智能體與環境不斷交互完成以下工作:(1)觀察當前環境狀態;(2)確定智能體的行為;(3)智能體執行相應動作;(4)將環境改變到另一個狀態:(5)得到對應于狀態變化的收益;(6)執行Q學習。采取一種逐場景的優化方法,Q值的計算應用卷積神經網絡訓練得到。
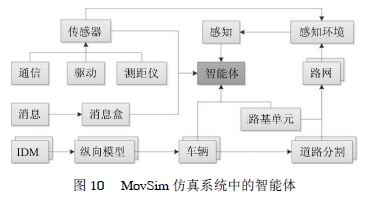
交通系統因其地理上分布性、處于動態環境中和子系統間需要,以一種靈活的方式交互而非常適合使用基于智能體的方法模擬仿真。GM等基于多模型開源車輛–交通仿真器MovSim套件進行擴展,提出協作式交通建模。利用多智能體系統中對環境的局部感知特性、信息交互、協作執行等特性,車輛完成協作式感知、決策和執行。
為降低緊急情況下智能車輛在路口等待時間和其他車輛的行駛時間,KT等設計一種可用于仿真智能車在交叉路口的控制系統,他們使用SUMO(SimulationofUrbanMobility)作為微觀交通仿真器,使用JADE(JavaAgentDevelopmentFrame-work)框架基于多智能體系統重現與真實交通系統相類似的仿真系統,引入Q學習使得交通燈智能體更加智能。交通仿真對于智能車的發展來說是至關重要的,因為真實環境中不可能人為制造特殊的場景來測試緊急情況下車輛的反應。
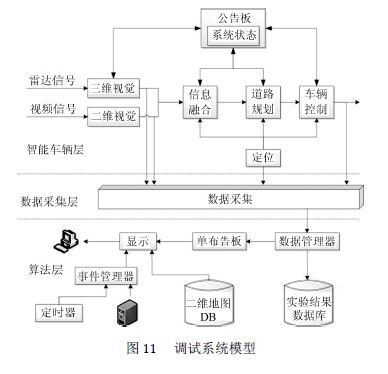
BN等基于多智能體技術為智能車設計了一種仿真調試系統,如圖11。
它使用一種分布式架構,將智能車的二維、三維、信息融合、道路規劃、車輛控制等建模成智能體,各智能體之間相互配合,有效提高了系統執行效率和執行時間。總結來說,基于智能體的交通仿真系統有如下優點:(1)系統可以在不使用真實場景設備的情況下測試、驗證;(2)虛擬世界中可以安全地對一些危險、極端的狀況進行復現;(3)數據可以被重復使用,仿真環境也可以非常方便地重復進行直至想要的結果出現;(4)仿真過程可以基于需求在時間維度進行擴展。
當前的智能車技術主要圍繞著單車智能體的發展,集中于無人干預下的環境感知、路徑規劃和行為決策。網聯汽車將通信技術與無人駕駛技術結合起來,從點到塊到網絡,使得從局部到全局的車輛協同感知、規劃以及信息交互得以實現,智能交通系統的可靠性、多功能性得到了提升。然而,網聯環境下系統元素的多樣性、時變性、復雜性以及“人車共駕”所導致的社會信號(SocialSignal)的引入,使得系統行為越來越難以被精確地刻畫,實際行為與模型行為差異性帶來的“模型鴻溝”為復雜的交通管理帶來了新的挑戰。
3 平行駕駛
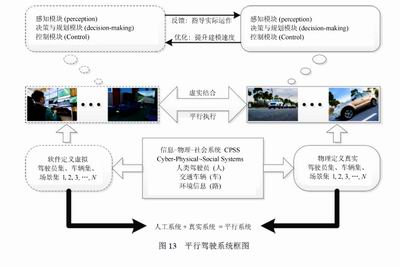
當前無人駕駛技術的發展還處于“人車共駕”的時代,人類行為的加入導致了智能交通系統復雜性的增加,社會信號的加入使得復雜系統從簡單的物理系統、信息物理系統,向著信息物理社會系統(Cyber-Physics-SocialSystems,CPSS)過渡。“建模鴻溝”的出現迫使我們從利用可以控制系統行為的“牛頓定律”進行建模,向著能夠影響系統行為的“默頓定律”進行轉化。默頓系統的典型特征就是即使給定其當前狀態與控制條件,也無法通過求解精確地預測系統的下一步狀態。網聯汽車作為一種CPSS系統也是一種典型的莫頓系統,以“車端感知,云端管控”為特征的基于ACP理論的平行駕駛理論為此尋找了一種好的解決方案。
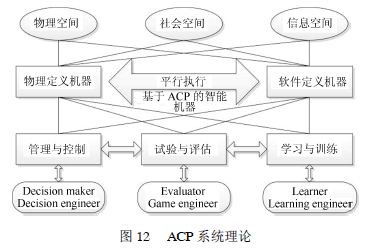
ACP理論包含人工系統(ArtificialSystem)、計算實驗(Computationalexperiment)和平行執行(Par-allelExecution),它提供了一種高效的解決復雜系統的方法,如圖12所示。基于CPSS的平行駕駛技術是以ACP理論為基礎的。ACP的結構如下:
傳統的車輛被認為是軟件定義車輛,未來的智能網聯汽車則包含3個主要部分:(1)車輛Agent(具有物理屬性);(2)人類駕駛員Agent(具有物理屬性和認知屬性);(3)與駕駛有關聯的控制Agent。
平行駕駛是新一代的云端化網聯自動駕駛技術,通過充分利用數字化及信息化資源,將云端、道路及車輛上的信息無縫銜接,利用平行視覺、平行感知、平行學習、平行規劃和平行控制等最新開發的前沿關鍵技術,把智能車、管控平臺及駕駛模擬器實時連接起來,提高了車輛對動態變化環境的響應速度,最終實現車路互動、多車協同、平行操控、安全行駛。
平行駕駛理論是基于信息物理社會系統(CPSS),通過將人工系統與真實系統虛實結合起來,它使用ACP方法,實現:
(1)利用自底向上的多Agent方法對人工場景中的對象及其相互關系進行建模,模擬實際交通場景中的動靜態特征;
(2)利用計算實驗方法對于人工場景中的Agent進行計算實驗,例如:使用機器學習方法對虛擬環境下的網聯汽車Agent進行并線、換道甚至是追尾等場景的控制策略進行評估,分析得到多Agent系統之間以何種策略進行信息交互、協同合作等;
(3)將計算實驗得到的控制算法在實際場景和人工場景中平行執行,使模型訓練和評估在線化、長期化。通過人工與實際之間的虛實互動,持續優化系統。
平行駕駛技術是傳統的基于Agent智能車控制技術的一次重要變革,它將智能汽車帶入到一個與現實世界平行的虛擬世界。基于CPSS理論基礎的“車內簡單、車外復雜”平行駕駛框架,以“車端感知、云端管控”為基本理念,利用智能車行駛狀態信息和交通環境信息結合虛擬系統的相關數據,通過大數據分析學習系統進行分析決策,實現對智能車的預測、指揮和控制。
為理解車聯網不同層次的結構和功能特性以及內在動力學特性,為混合交通形態下的系統管理提供科學的解決方案,WANG等將ACP方法推廣到車聯網領域,提出了一種新的智能車輛網聯管理與控制系統:平行車聯網。平行車聯網由3步構成。
第1步:人工車聯網,“生長型”系統模型構建與培育。其本質是利用人工社會的理論與方法構建可計算、可編程、可重構的軟件定義對象。采用多Agent方法對系統建模,通過定義Agent之間的交互規則、組織規則和協同行為規則,構建適用于不同交通場景的人工車聯網子系統。
第2步:計算實驗,智能車輛網聯管理與控制策略的試驗與評估。基于人工車聯網設計各類Agent的數量組合策略及時序互動規則,生成各種復雜的交通場景,以計算的手段讓車輛學習經驗知識用于分析與評估。
第3步:平行執行,車聯網的智能引導管理與控制。平行車聯網綜合考慮車內網、車際網、車路網以及社會網的平行,實際車聯網向平行車聯網提供用于建立和優化人工車聯網模型的狀態參數,人工車聯網中的計算實驗結果以虛實互動的平行執行方式反饋給實際車聯網,循環往復,協同優化。
平行車聯網以可計算、可實現、可比較的方式對復雜車聯網系統不同層次和功能特性進行解析,為未來智能交通控制與管理提供新思路。
作為CPSS系統中社會信號一部分的法律法規對于規范智能汽車的行為決策具有重要的意義。目前,針對無人駕駛車輛上路的法律法規尚不健全,為此,Intel聯合Mobileye提出了責任–敏感–安全(Responsibility-Sensitive-Safety)的RSS模型。概括起來說,RSS模型規定了車輛行駛過程中的路權以被給予而非爭奪的方式取得。RSS模型中將無人駕駛車輛看成是多智能體系統,類似于人類駕駛,事故情況下的權責是不等的,這也適用于多智能體系統,RSS模型以“定責”的方式給車輛行駛定下規則,從而保證無人車成為緊急情況下事故參與者而非制造者。對此以數學模型的方式給出了4個常識為:
(1)與前方車輛保持安全距離,對于緊急剎車及時作出判斷;同向行駛的車輛必須保持一定的剎車安全距離避免追尾發生,安全距離依賴于反應時間t、最大加速加速度amax;accel,最大剎車加速度amax;brake,最小剎車加速度amin;brake幾個參數。
對于無人駕駛車輛與有人駕駛車輛混合的場景,機器人與人的反應時間t是不一樣的,不同天氣狀況下的參數也是不一樣的。RSS模型同時給出了碰撞發生閾值時間,并基于此決定碰撞責任該歸咎于反應不夠快的智能體系統。
(2)基于車輛動力學原理,與側面車輛保持安全距離,在進行側向并線時給側向車輛留出足夠反應時間;
(3)路權是被給予的,而非爭奪的;在多幾何結構的道路中往往涉及到路權分配的問題。例如紅綠燈路口不僅僅依照紅燈停和綠燈行的規則,智能體還需要考慮避免事故的因素。
(4)對于遮擋區域和行人保持足夠警惕。在駕駛策略的選擇上依然采用強化學習的方法,不同于傳統的幾何描述的動作空間,RSS模型使用一種語義描述動作空間的方法,來解決求解Q函數時計算復雜的問題。在語義動作空間使用類似“跟隨超車,從左側超車”等的語義指令代替向前開13m后以0。8m/s2的加速度前進的數值指令,語義指令在降低計算資源的基礎上,可以獲得未來較長時間內行駛品質的比較精確的估計。
RSS將人們對安全駕駛的概念轉化為可驗證的模型,配備邏輯上可驗證的規則,定義恰當的響應行為,以確保自動駕駛汽車做出安全決策,并避免陷入由其他車輛導致的危險情況。
4 總結與展望
本文對基于Agent的智能汽車控制進行總結。單個智能汽車由于其具有感知、規劃和決策能力,而其本身軟硬件平臺是由多個復雜的模塊構成,非常適合使用Agent技術對其進行建模,用于處理類似多傳感器數據融合等任務,從而保證系統可靠工作,降低能耗。車與人、車與車、車與道路基礎設施等構成的車聯網系統,則進一步擴大了Agent技術的應用。在通信的情況下,智能車Agent不再完全依賴與自身的環境感知系統,而是可以在云端Agent協同控制下與其他Agent系統進行必要信息的共享。基于Agent的智能交通系統使得智能汽車Agent擁有更多的環境信息,能夠更準確地對環境中的不確定性因素進行分析,從而更好地、更安全地運行。
來源:控制網、科學網