視覺Transformer研究的關鍵問題: 現(xiàn)狀及展望
發(fā)布時間:2022-06-22 17:55:50
Transformer所具備的長距離建模能力和并行計算能力使其在自然語言處理領域取得了巨大成功并逐步拓展至計算機視覺等領域. 本文以分類任務為切入, 介紹了典型視覺Transformer的基本原理和結構
摘要: Transformer所具備的長距離建模能力和并行計算能力使其在自然語言處理領域取得了巨大成功并逐步拓展至計算機視覺等領域. 本文以分類任務為切入, 介紹了典型視覺Transformer的基本原理和結構, 并分析了Transformer與卷積神經(jīng)網(wǎng)絡在連接范圍、權重動態(tài)性和位置表示能力三方面的區(qū)別與聯(lián)系; 同時圍繞計算代價、性能提升、訓練優(yōu)化以及結構設計四個方面總結了視覺Transformer研究中的關鍵問題以及研究進展; 并提出了視覺Transformer的一般性框架; 然后針對檢測和分割兩個領域, 介紹了視覺Transformer在特征學習、結果產(chǎn)生和真值分配等方面給上層視覺模型設計帶來的啟發(fā)和改變; 并對視覺Transformer未來發(fā)展方向進行了展望.
Key Problems and Progress of Vision Transformers:
The State of the Art and Prospects
TIAN Yong-Lin, WANG Yu-Tong, WANG Jian-Gong, WANG Xiao, WANG Fei-Yue
Abstract: Due to its long-range sequence modeling and parallel computing capability, Transformers have achieved significant success in natural language processing and are gradually expanding to computer vision area. Starting from image classification, we introduce the architecture of classic vision Transformer and compare it with convolutional neural networks in connection range, dynamic weights and position representation ability. Then, we summarize existing problems and corresponding solutions in vision Transformers including computational efficiency, performance improvement, optimization and architecture design. Besides, we propose a general architecture of Vision Transformers. For object detection and image segmentation, we discuss Transformer-based models and their roles on feature extraction, result generation and ground-truth assignment. Finally, we point out the development trends of vision Transformers.
Key words: Vision Transformers / image classification / object detection / image segmentation / computer vision
深度神經(jīng)網(wǎng)絡(Deep neural network, DNN)由于其突出的性能表現(xiàn), 已經(jīng)成為人工智能系統(tǒng)的主流模型之一[1-2]. 針對不同的任務, DNN發(fā)展出了不同的網(wǎng)絡結構和特征學習范式. 其中, 卷積神經(jīng)網(wǎng)絡(Convolutional neural network, CNN)[3-5]通過卷積層和池化層等具備平移不變性的算子處理圖像數(shù)據(jù); 循環(huán)神經(jīng)網(wǎng)絡(Recurrent neural network, RNN)[6-7]通過循環(huán)單元處理序列或時序數(shù)據(jù). Transformer[8]作為一種新的神經(jīng)網(wǎng)絡結構, 目前已被證實可以應用于自然語言處理(Natural language processing, NLP)、計算機視覺(Computer vision, CV)和多模態(tài)等多個領域, 并在各項任務中展現(xiàn)出了極大的潛力.
Transformer[8]興起于NLP領域, 它的提出解決了循環(huán)網(wǎng)絡模型, 如長短期記憶(Long short-term memory, LSTM)[6]和門控循環(huán)單元(Gate recurrent unit, GRU)[7]等存在的無法并行訓練, 同時需要大量的存儲資源記憶整個序列信息的問題. Transformer[8]使用一種非循環(huán)的網(wǎng)絡結構, 通過編碼器?解碼器以及自注意力機制[9-12]進行并行計算, 大幅縮短了訓練時間, 實現(xiàn)了當時最優(yōu)的機器翻譯性能. Transformer模型與循環(huán)神經(jīng)網(wǎng)絡以及遞歸神經(jīng)網(wǎng)絡均具備對序列數(shù)據(jù)的特征表示能力, 但Transformer打破了序列順序輸入的限制, 以一種并行的方式建立不同詞符間的聯(lián)系. 基于Transformer模型, BERT[13]在無標注的文本上進行了預訓練, 最終通過精調輸出層, 在11項NLP任務中取得了最優(yōu)表現(xiàn). 受BERT啟發(fā), 文獻[14]預訓練了一個名為GPT-3的擁有1 750億個參數(shù)的超大規(guī)模Transformer模型, 在不需要進行精調的情況下, 這一模型在多種下游任務中表現(xiàn)出強大的能力. 這些基于Transformer模型的工作, 極大地推動了NLP領域的發(fā)展.
Transformer在NLP領域的成功應用, 使得相關學者開始探討和嘗試其在計算機視覺領域的應用[15-16]. 一直以來, 卷積神經(jīng)網(wǎng)絡都被認為是計算機視覺的基礎模型. 而Transformer的出現(xiàn), 為視覺特征學習提供了一種新的可能[17-21]. 基于Transformer的視覺模型在圖像分類[15, 22-23]、目標檢測[16, 24]、圖像分割[25-26]、視頻理解[27-28]、圖像生成[29]以及點云分析[30-31]等領域取得媲美甚至領先卷積神經(jīng)網(wǎng)絡的效果.
將Transformer應用于視覺任務并非一個自然的過程, 一方面, Transformer網(wǎng)絡以序列作為輸入形式, 其本身并不直接適用于二維的圖像數(shù)據(jù)[15-16], 將其適配到視覺任務需要經(jīng)過特殊設計; 另一方面基于全局信息交互的Transformer網(wǎng)絡往往具有較大的計算量, 同時對數(shù)據(jù)量也有較高要求, 因此需要考慮其效率以及訓練和優(yōu)化等問題[32-33]. 此外, Transformer所定義的基于注意力的全局交互機制是否是一種完備的信息提取方式, 來自CNN中的經(jīng)驗和技巧能否幫助Transformer在計算機視覺任務中取得更好的性能也是需要思考的問題[34-35].
同其他Transformer相關的綜述文獻[17-19]相比, 本文的區(qū)別和主要貢獻在于我們以視覺Transformer在應用過程中存在的關鍵問題為角度進行切入, 針對每個關鍵問題組織并綜述了相關文章的解決方案和思路, 而其他文獻[17-19]則更多是從技術和方法分類的角度入手. 本文梳理了Transformer在計算機視覺中應用中的若干關鍵問題, 同時總結了Transformer在計算機視覺的分類、檢測和分割任務中的應用和改進. 本文剩余部分組織如下: 第 1 節(jié)以ViT[15]為例介紹視覺Transformer的原理和基本組成, 并對比了Transformer與CNN的區(qū)別和聯(lián)系, 同時總結了Transformer的優(yōu)勢和劣勢; 第 2 節(jié)給出了視覺Transformer的一般性框架; 第 3 節(jié)介紹Transformer研究中的關鍵問題以及對應的研究進展; 第 4 節(jié)介紹Transformer在目標檢測領域的應用; 第 5 節(jié)介紹Transformer在圖像分割領域的應用; 第 6 節(jié)總結了全文并展望了視覺Transformer的發(fā)展趨勢.
1. ViT原理介紹與分析
ViT[15]將Transformer結構完全替代卷積結構完成分類任務, 并在超大規(guī)模數(shù)據(jù)集上取得了超越CNN的效果[36-39]. ViT結構如圖1所示, 它首先將輸入圖像裁剪為固定尺寸的圖像塊, 并對其進行線性映射后加入位置編碼, 輸入到標準的Transformer編碼器. 為了實現(xiàn)分類任務, 在圖像塊的嵌入序列中增加一個額外的可學習的類別詞符(Class token).
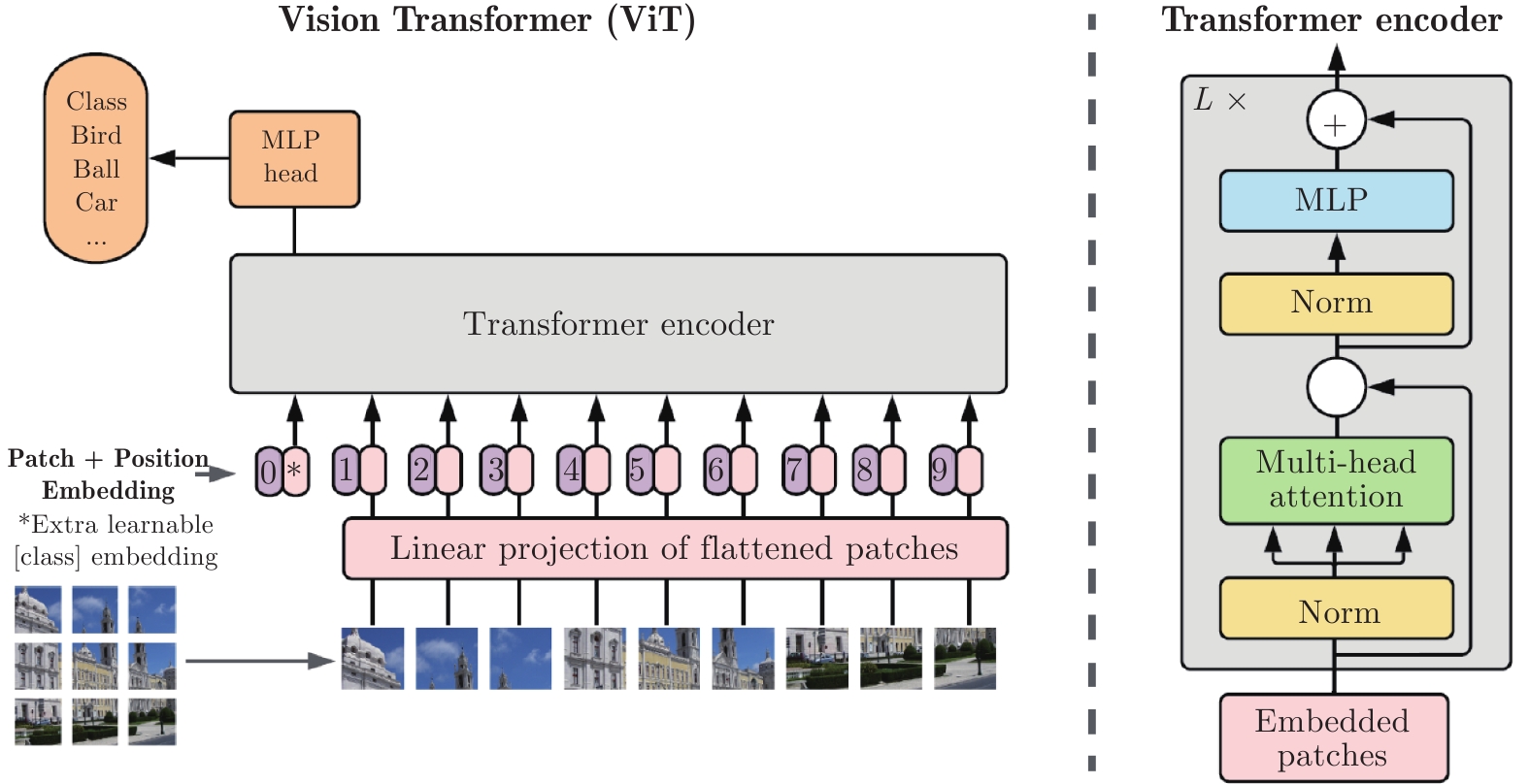
圖 1 ViT模型結構[15]
Fig. 1 The framework of ViT[15]
1.1 圖像序列化
對于NLP任務, Transformer的輸入是一維的詞符嵌入向量, 而視覺任務中, 需要處理的是二維的圖像數(shù)據(jù). 因此, ViT[15]首先將尺寸為H×W×C的圖像![]() 裁剪為N=HW/P2個尺寸為P×P×C的圖像塊, 并將每個圖像塊展開成一維向量, 最終得到
裁剪為N=HW/P2個尺寸為P×P×C的圖像塊, 并將每個圖像塊展開成一維向量, 最終得到![]() . 記d為Transformer輸入嵌入向量的維度, ViT[15]將xp進行線性映射, 并與類別詞符一起組成為d維z0, 如式(1)所示, 作為Transformer編碼器的輸入.
. 記d為Transformer輸入嵌入向量的維度, ViT[15]將xp進行線性映射, 并與類別詞符一起組成為d維z0, 如式(1)所示, 作為Transformer編碼器的輸入.
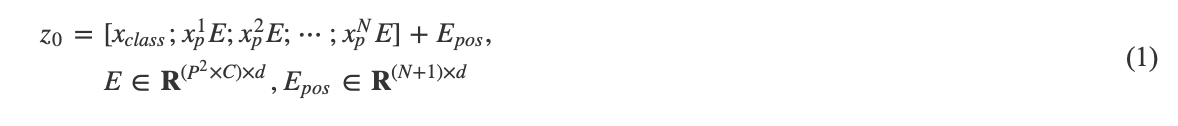
其中, ![]() 是為了實現(xiàn)分類任務加入的可學習的類別詞符, E是實現(xiàn)線性映射的矩陣, Epos是位置編碼. 類別詞符以網(wǎng)絡參數(shù)的形式定義, 其本身是一種網(wǎng)絡權重, 可以通過梯度進行更新. 類別詞符
是為了實現(xiàn)分類任務加入的可學習的類別詞符, E是實現(xiàn)線性映射的矩陣, Epos是位置編碼. 類別詞符以網(wǎng)絡參數(shù)的形式定義, 其本身是一種網(wǎng)絡權重, 可以通過梯度進行更新. 類別詞符![]() 本身不具備當前輸入的特征和信息, 而是在與圖像塊詞符串聯(lián)后通過自注意力機制實現(xiàn)對圖像特征的信息交互或信息聚合, 在編碼器最后一層之后, 類別詞符
本身不具備當前輸入的特征和信息, 而是在與圖像塊詞符串聯(lián)后通過自注意力機制實現(xiàn)對圖像特征的信息交互或信息聚合, 在編碼器最后一層之后, 類別詞符![]() 作為對圖像特征的聚合, 被送入分類頭進行類別預測.
作為對圖像特征的聚合, 被送入分類頭進行類別預測.
1.2 編碼器
ViT[15]的編碼器由L(ViT[15]中, L= 6)個相同的層堆疊而成, 每個層又由兩個子層組成. 其中, 第一個子層是多頭自注意力機制(Multi-head self-attention, MSA), 第二個子層是多層感知機(Multi-layer perceptron, MLP). 在數(shù)據(jù)進入每個子層前, 都使用層歸一化(Layer normalization, LN)[40]進行歸一化處理, 數(shù)據(jù)經(jīng)過每個子層后, 又使用殘差連接與輸入進行直接融合. 值得注意的是, 為了實現(xiàn)殘差連接[5], ViT編碼器的每一層的輸出維度都設計為d維. 最后, 經(jīng)過L層網(wǎng)絡編碼之后, 類別詞符![]() 被送入到由MLP構成的分類頭中, 從而預測得到圖像的類別y. 第l層的特征計算過程如下:
被送入到由MLP構成的分類頭中, 從而預測得到圖像的類別y. 第l層的特征計算過程如下:
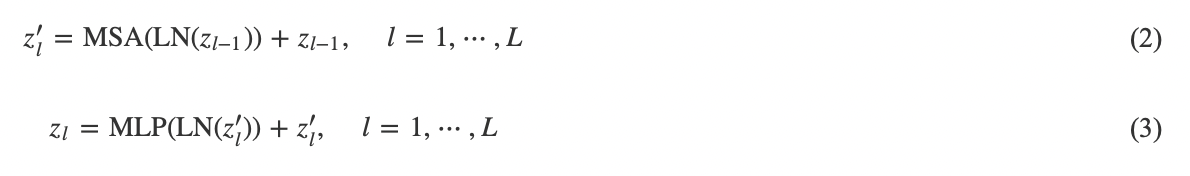
類別預測結果的產(chǎn)生可表示為:
![]()
1.3 注意力機制
注意力機制(Attention)最早應用于NLP任務中[9, 12, 41], 通過引入長距離上下文信息, 解決長序列的遺忘現(xiàn)象. 在視覺任務中, 注意力機制同樣被用來建立空間上的長距離依賴, 以解決卷積核感受野有限的問題[42-43].
ViT使用的自注意力機制(Self-attention, SA)是一種縮放點積注意力(Scaled dot-product attention), 其計算過程如圖2所示. 自注意力層通過查詢(Query)與鍵(Key)-值(Value)對之間的交互實現(xiàn)信息的動態(tài)聚合. 對輸入序列![]() , 通過線性映射矩陣UQKV將其投影得到Q、K和V三個向量. 在此基礎上, 計算Q和K間的相似度A, 并根據(jù)A實現(xiàn)對V進行加權. 自注意力的計算過程如下所示:
, 通過線性映射矩陣UQKV將其投影得到Q、K和V三個向量. 在此基礎上, 計算Q和K間的相似度A, 并根據(jù)A實現(xiàn)對V進行加權. 自注意力的計算過程如下所示:
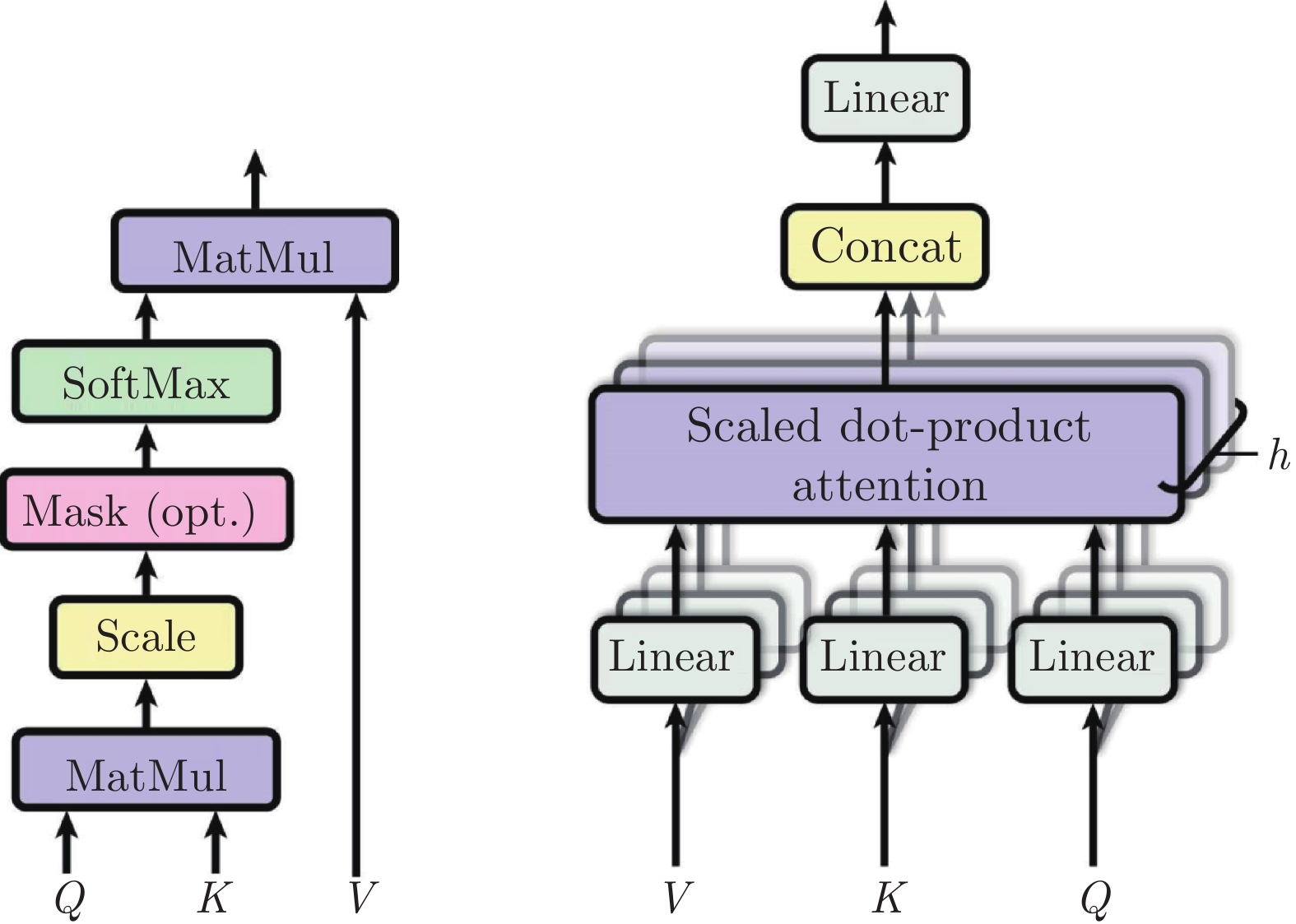
圖 2 自注意力[15]與多頭自注意力[15]
Fig. 2 Self-attention[15]and multi-head self-attention[15]
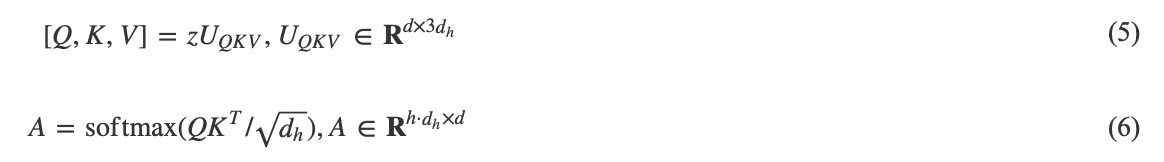
加權聚合過程可表示為:
![]()
為了提高特征多樣性, ViT使用了多頭自注意力機制. 多頭自注意力層使用多個自注意力頭來并行計算, 最后通過將所有注意力頭的輸出進行拼接得到最終結果. 多頭注意力計算過程如下所示:
![]()
其中, ![]() 為映射矩陣, 用于對拼接后的特征進行聚合, h表示自注意力頭的個數(shù), dh為每個自注意力頭的輸出維度. 為了保證在改變h時模型參數(shù)量不變, 一般將dh設置為d/h. 多頭自注意力機制中并行使用多個自注意力模塊, 可以豐富注意力的多樣性, 從而增加模型的表達能力.
為映射矩陣, 用于對拼接后的特征進行聚合, h表示自注意力頭的個數(shù), dh為每個自注意力頭的輸出維度. 為了保證在改變h時模型參數(shù)量不變, 一般將dh設置為d/h. 多頭自注意力機制中并行使用多個自注意力模塊, 可以豐富注意力的多樣性, 從而增加模型的表達能力.
1.4 位置編碼
ViT使用了絕對位置編碼來彌補圖像序列化丟失的圖像塊位置信息. 位置編碼信息與特征嵌入相加后被送入編碼器進行特征交互. ViT使用的位置編碼由不同頻率的正弦和余弦函數(shù)構成, 其計算過程如下:
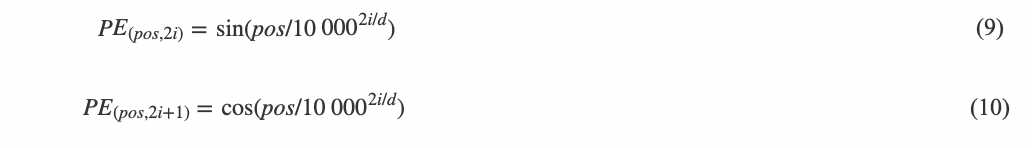
其中, pos是每個圖像塊在圖像中的位置, i∈[0,?,d/2]用于計算通道維度的索引. 對于同一個i, 通道上第2i和2i+1個位置的編碼是具有相同角速度的正弦和余弦值. 為了使得位置編碼可以與輸入嵌入相加, 位置編碼需要與嵌入保持相同的維度.
1.5 Transformer同卷積神經(jīng)網(wǎng)絡的區(qū)別與聯(lián)系
本節(jié)主要從連接范圍[44]、權重動態(tài)性[44]和位置表示能力三個方面來闡述Transformer同卷積神經(jīng)網(wǎng)絡的區(qū)別與聯(lián)系.
1.5.1 連接范圍
卷積神經(jīng)網(wǎng)絡構建在輸入的局部連接之上, 通過不斷迭代, 逐漸擴大感受野, 而Transformer則具備全局交互機制, 其有效感受野能夠迅速擴大. 圖3展示了語義分割任務中, DeepLabv3+[45]和SegFormer[25]在有效感受野上的對比, 可以看到, 相比于卷積神經(jīng)網(wǎng)絡, Transformer網(wǎng)絡的有效感受野范圍具備明顯優(yōu)勢. 雖然卷積核的尺寸可以設置為全圖大小, 但這種設置在圖像數(shù)據(jù)處理中并不常見, 因為這將導致參數(shù)量的顯著增加.
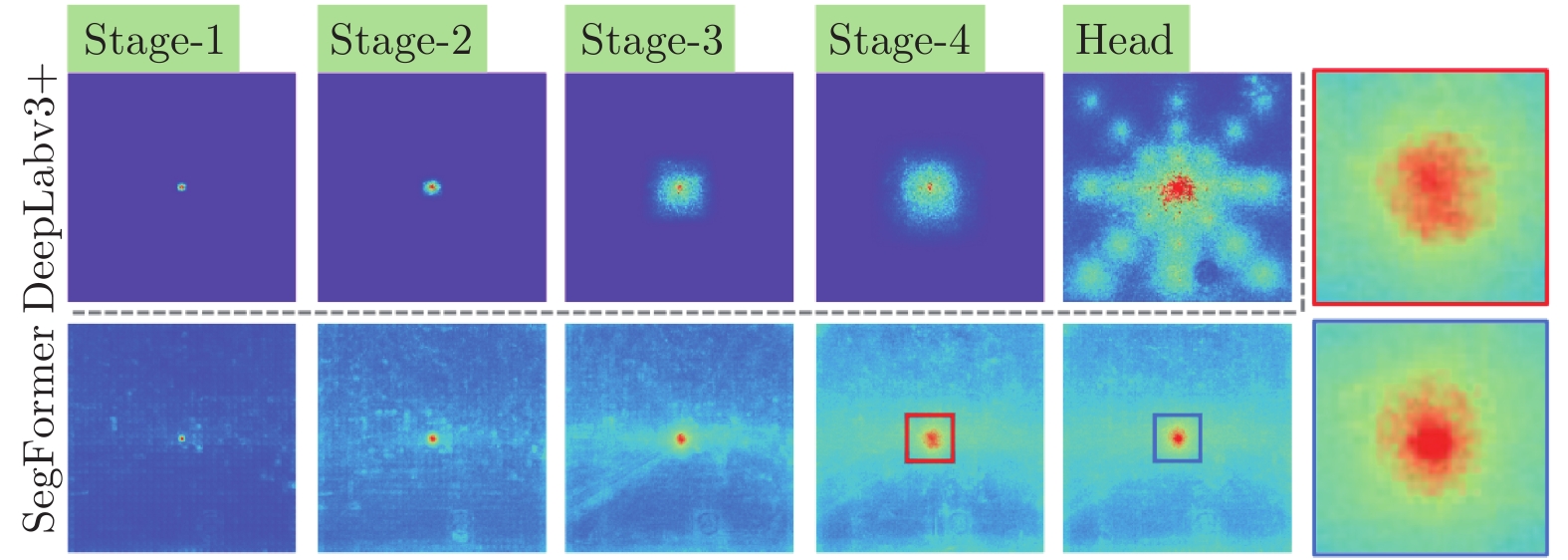
圖 3 Transformer與CNN有效感受野對比[25]
Fig. 3 The comparison[25] of effective receptive field between Transformer and CNN
1.5.2 權重動態(tài)性
傳統(tǒng)卷積神經(jīng)網(wǎng)絡在訓練完成后, 卷積核權重不隨輸入或滑動窗口位置變化而改變[46], 而Transformer網(wǎng)絡通過相似性度量動態(tài)地生成不同節(jié)點的權重并進行信息聚合. Transformer的動態(tài)性與動態(tài)卷積[46]具備相似的效果, 都能響應輸入信息的變化.
1.5.3 位置表示能力
Transformer使用序列作為輸入形式, 其所使用的自注意力機制和通道級MLP模塊均不具備對輸入位置的感知能力, 因此Transformer依賴位置編碼來實現(xiàn)對位置信息的補充. 相比之下, 卷積神經(jīng)網(wǎng)絡處理二維圖像數(shù)據(jù), 一方面卷積核中權重的排列方式使其具備了局部相對位置的感知能力, 另一方面, 有研究表明[47], 卷積神經(jīng)網(wǎng)絡使用的零填充(Zero padding)使其具備了絕對位置感知能力, 因此, 卷積神經(jīng)網(wǎng)絡不需要額外的位置編碼模塊.
1.6 ViT的優(yōu)劣勢分析
ViT[15]模型的優(yōu)勢在于其構建了全局信息交互機制, 有助于建立更為充分的特征表示. 此外, ViT采用了Transformer中標準的數(shù)據(jù)流形式, 有助于同其他模態(tài)數(shù)據(jù)進行高效融合. ViT存在的問題主要在三個方面, 首先全局注意力機制計算量較大, 尤其是面對一些長序列輸入時, 其與輸入長度成平方的計算代價極大地限制了其在高分辨率輸入和密集預測任務中的應用; 其次, 不同于卷積中的局部歸納偏置, ViT模型從全局關系中挖掘相關性, 對數(shù)據(jù)的依賴較大, 需要經(jīng)過大量數(shù)據(jù)的訓練才能具備較好效果; 此外, ViT模型的訓練過程不穩(wěn)定且對參數(shù)敏感.
2. Transformer研究中的關鍵問題
本節(jié)以圖像分類這一基本的視覺任務為切入, 著重介紹Transformer在用于視覺模型骨架時的關鍵研究問題以及對應的研究進展.
2.1 如何降低Transformer的計算代價
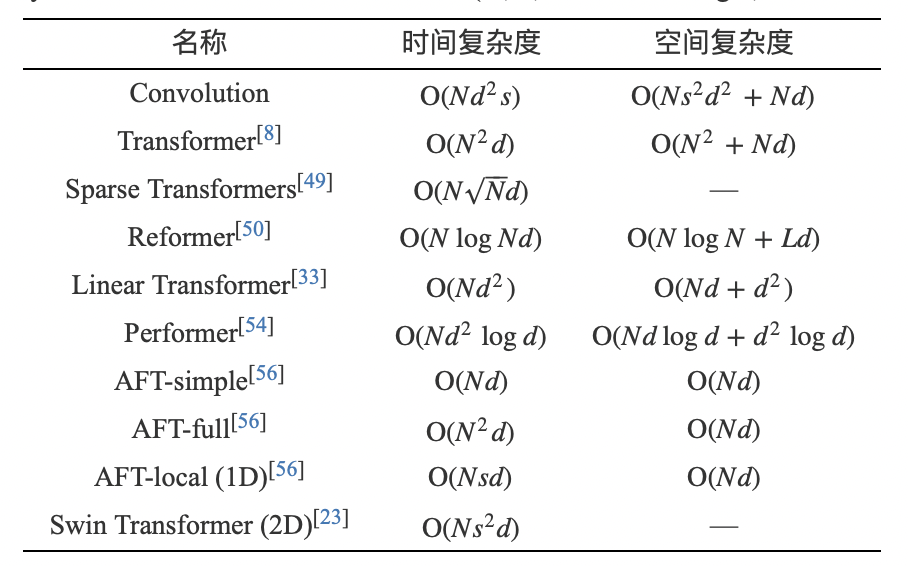
Transformer的設計使其具有全局交互能力, 但同時其全局自注意力機制也帶來了較高的時間和空間代價, 如何設計更高效的Transformer機制成為研究熱點之一[48]. 原始的Transformer使用了點積注意力機制(Dot-product attention), 其具有二次的時間和空間復雜度, 因此不利于推廣到高分辨率圖像和特征的處理中. 現(xiàn)有文獻主要從輸入和注意力設計兩個角度來降低Transformer注意力機制的復雜度. 表1總結了多種Transformer模型的自注意力機制的計算復雜度.
表 1 不同Transformer自注意力機制以及卷積的時間和空間復雜度(N, d, s分別表示序列長度、特征維度和局部窗口尺寸, 其中s<N)
Table 1 The time and space complexity of different Transformer frameworks (N, d, sdenote the length, dimension and local window size respectively)
2.1.1 受限輸入模式
減少輸入到注意力層的序列的長度是降低計算量的直接手段, 現(xiàn)有文獻主要從輸入下采樣、輸入局部化和輸入稀疏化三個角度來限制序列的長度[49].
1) 輸入下采樣: PVT[22]通過金字塔型的網(wǎng)絡設計將圖像分辨率層級尺度衰減, 來逐漸降低圖像序列的長度. DynamicViT[51]通過輸入學習動態(tài)的序列稀疏化策略, 以此逐漸降低圖像序列長度. 該類方法在維持全局交互的基礎上, 以減小分辨率的形式實現(xiàn)對計算量的降低.
2) 輸入局部化: 輸入局部化旨在限制注意力的作用范圍, 通過設計局部的注意力機制降低計算量, 例如Swin Transformer[23]提出了基于窗口的多頭注意力機制, 將圖像劃分成多個窗口, 僅在窗口內部進行交互.
3) 輸入稀疏化: 稀疏化通過采樣或壓縮輸入來降低注意力矩陣的尺寸, 例如, CrossFormer[52]提出了對輸入進行間隔采樣來構建長距離注意力(Long distance attention). Deformable DETR[24]將可形變卷積的設計引入到注意力的計算中, 通過學習采樣點的位置信息實現(xiàn)稀疏交互機制, 在減小計算量的同時維持了較大范圍的感受野.
2.1.2 高效注意力機制
核函數(shù)方法[33]和低秩分解[53]是用來降低注意力復雜度的主要方法[48]. 表1中總結了不同注意力機制的時間復雜度和空間復雜度, 同時我們給出了卷積算子的復雜度作為參考. 為了方便對比, 我們在卷積復雜度的計算中, 將特征圖的長寬乘積等同于Transformer的輸入序列長度, 將Transformer的詞符特征的維度視為卷積輸入與輸出通道數(shù), 將局部Transformer的窗口大小s
視為卷積核大小.
1) 核函數(shù)方法(Kernelization): 核函數(shù)方法通過重構注意力計算機制打破歸一化函數(shù)對Q和K計算的綁定, 來降低注意力計算的時間和空間成本[33, 54-55]. 點積注意力機制可被表示為如下形式:
![]()
其中, ρ表示激活函數(shù), 在經(jīng)典Transformer[8]中, 激活函數(shù)為Softmax. Efficient attention[32]和Linear Transformer[33]將注意力機制的計算轉換為式(12)的形式, 實現(xiàn)對點積注意力的近似.
![]()
這種方式避免了對具有O(N2)時間和空間復雜度的注意力圖的計算和存儲, 提高了注意力的計算效率. AFT[56]采用了類似式(12)的設計, 但使用逐元素相乘代替矩陣的點積運算, 從而進一步降低了計算量.
2) 低秩方法(Low-rank methods): 低秩分解假定了注意力矩陣是低秩的, 因此可以將序列長度進行壓縮以減少計算量. 考慮到注意力層輸出序列長度只與查詢的節(jié)點個數(shù)有關, 因此通過壓縮鍵和值向量的序列長度, 不會影響最終輸入的尺寸. PVT[22]、ResT[53]和CMT[34]利用卷積減少了鍵和值對應的詞符個數(shù)以降低計算量. SOFT[57]使用高斯核函數(shù)替換Softmax點積相似度, 并通過卷積或池化的方式從序列中采樣, 實現(xiàn)對原始注意力矩陣的低秩近似.
2.2 如何提升Transformer的表達能力
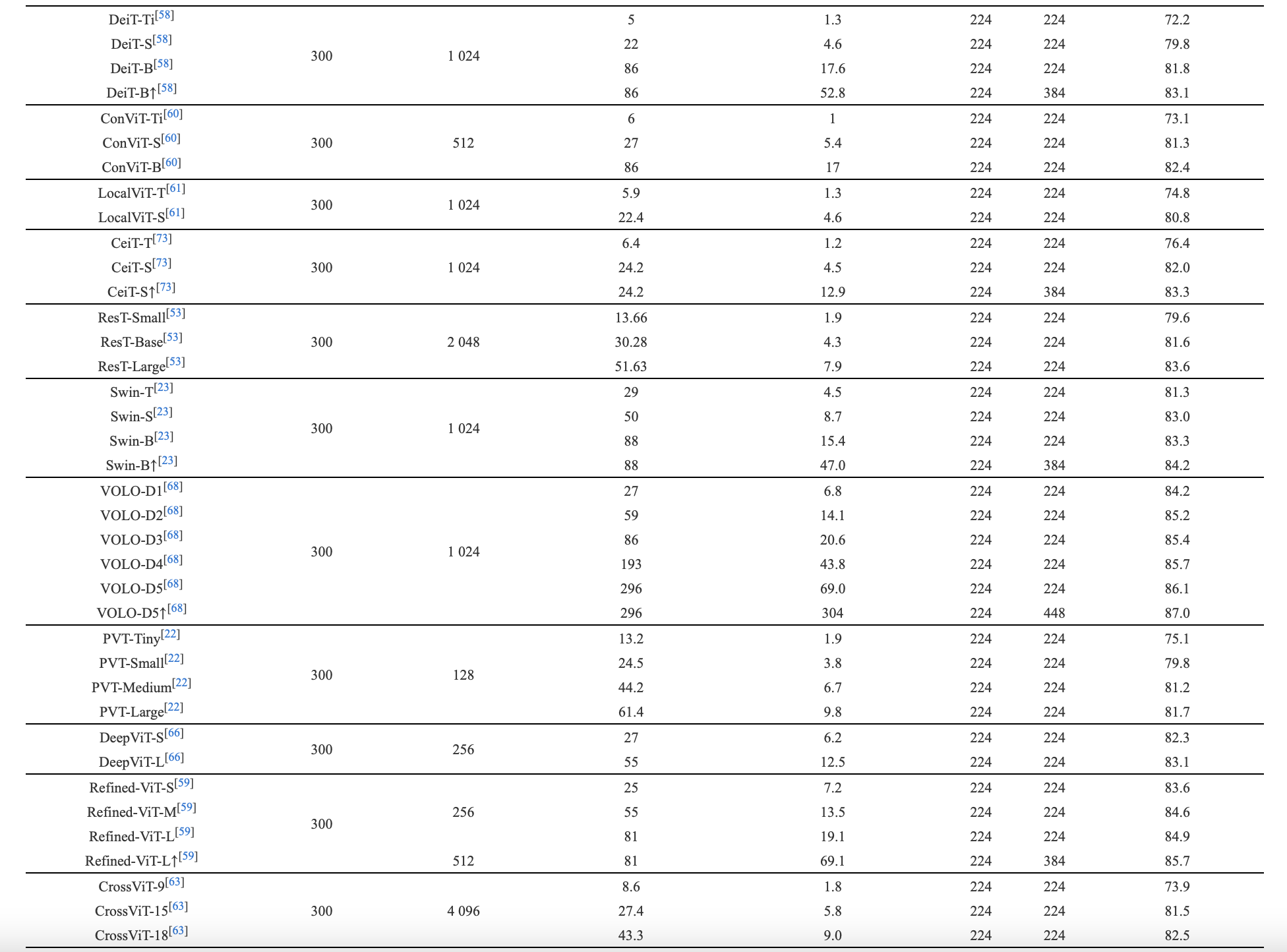
本小節(jié)主要圍繞如何提高Transformer模型的表達能力而展開, 視覺Transformer的研究仍處于起步階段, 一方面可以借鑒CNN的改進思路, 通過類似多尺度等的方案實現(xiàn)對性能的提升, 另一方面由于Transformer基于全局信息的交互, 使其具有不同于CNN的特征提取范式, 從而為引入CNN設計范式進而提升性能提供了可能. CNN的局部性(Locality)設計范式可以豐富Transformer網(wǎng)絡的特征多樣性, 同時也有利于改善Transformer特征的過度光滑(Over-smoothing)的問題[59]. 此外, 對Transformer本身機制, 如注意力和位置編碼等的改進也有望提高其表達能力. 表2展示了不同Transformer模型在ImageNet[4]上的性能對比.
表 2 視覺Transformer算法在ImageNet-1k上的Top-1準確率比較
Table 2 The comparison of Top-1 accuracy of different vision Transformers on ImageNet-1k dataset
2.2.1 多尺度序列交互
多尺度特征在CNN中已經(jīng)獲得了較為廣泛的應用[62], 利用多尺度信息能夠很好地結合高分辨率特征和高語義特征, 實現(xiàn)對不同尺度目標的有效學習. 在視覺Transformer中, CrossViT[63]使用兩種尺度分別對圖像進行劃分并獨立編碼, 對編碼后的多尺度特征利用交互注意層實現(xiàn)兩種尺度序列之間的信息交互. CrossFormer[52]則借助金字塔型網(wǎng)絡, 在不同層得到不同尺度的特征, 之后融合不同層的特征, 以進行跨尺度的信息交互.
2.2.2 圖像塊特征多樣化
DiversePatch[64]發(fā)現(xiàn)了在Transformer的深層網(wǎng)絡中, 同層圖像塊的特征之間的相似性明顯增大, 并指出這可能引起Transformer性能的退化, 使其性能無法隨深度增加而繼續(xù)提升. 基于該發(fā)現(xiàn), DiversePatch[64]提出了三種方式來提高特征的多樣性. 首先, 對網(wǎng)絡最后一層的圖像塊特征之間計算余弦相似度, 并作為懲罰項加入到損失計算中. 其次, 基于對Transformer網(wǎng)絡首層圖像塊特征多樣性較高的觀察, DiversePatch提出使用對比損失(Contrastive loss)來最小化同一圖像塊在首層和尾層對應特征的相似性, 而最大化不同圖像塊在首層和尾層對應特征的相似性. 最后, 基于CutMix[65]的思想, DiversePatch提出了混合損失(Mixing loss), 通過將來自不同圖片的圖像塊進行混合, 使網(wǎng)絡學習每個圖像塊的類別, 以避免特征同質化.
2.2.3 注意力內容多樣化
DeepViT[66]觀察到Transformer中的注意力坍塌(Attention collapse)現(xiàn)象, 即隨著網(wǎng)絡加深, 深層注意力圖不同層之間的相似性逐漸增大甚至趨同, 并指出注意力相似性增加和特征圖相似性增加有密切關系, 從而導致了Transformer性能隨層數(shù)增加而快速飽和. 為了避免注意力坍塌現(xiàn)象, DeepViT提出了增加詞符的嵌入維度的方法和重注意力(Re-attention)機制. 增加詞符的嵌入維度有助于詞符編碼更多信息, 從而提高注意力的多樣性, 但同時會帶來參數(shù)量的顯著增加. 重注意力機制基于層內多頭注意力的多樣性較大的現(xiàn)象, 通過對多頭注意力以可學習的方式進行動態(tài)組合來提高不同層注意力的差異. 重注意力機制R可表示為式(13)的形式, 其中Θ∈Rh×h.
![]()
Refiner[59]基于類似的思想提出了注意力擴張(Attention expansion)和注意力縮減(Attention reduction)模塊, 通過學習多頭注意力的組合方式來構建多樣化的注意力, 并可靈活拓展注意力的個數(shù). 同時, Refiner提出使用卷積來增強注意力圖的局部特征, 從而降低注意力圖的光滑程度.
2.2.4 注意力形式多樣化
經(jīng)典Transformer中的注意力機制依賴點對間的交互來計算其注意力, 其基本作用是實現(xiàn)自我對齊, 即確定自身相對于其他節(jié)點信息的重要程度[67]. Synthesizer[67]指出這種通過點對交互得到的注意力有用但卻并不充分, 通過非點對注意力能夠實現(xiàn)對該交互方式的有效補充.
1) 非點對注意力(Unpaired attention): Synthesizer[67]提出了兩種新的非點對注意力實現(xiàn)方法, 即基于獨立詞符和全局任務信息的注意力計算方法. 基于獨立詞符的注意力, 以每一個詞符為輸入, 在不經(jīng)過與其他詞符交互的情況下, 學習其他詞符相對于當前詞符的注意力; 基于全局任務信息的注意力生成方法則完全擺脫注意力對當前輸入的依賴, 通過定義可訓練參數(shù)從全局任務信息中學習注意力. 這兩種方式可視為從不同的角度來拓展注意力機制, 實驗驗證了它們同基于點對的注意力能形成互補關系. VOLO[68]同樣提出了基于獨立詞符的注意力生成方法, 并將注意力的范圍限制在局部窗口內, 形成了類似動態(tài)卷積的方案.
2.2.5 Transformer與CNN的結合
局部性是CNN的一個典型特征, 它是基于臨近像素具有較大相關性的假設而形成的一種歸納偏置(Inductive bias)[69-71]. 相比之下, Transformer的學習過程基于全局信息的交互, 因此在學習方式和特征性質等方面與CNN存在一定差異[72], 將CNN與Transformer進行結合有助于提升Transformer網(wǎng)絡對特征的學習和表達能力[23, 58, 73-74]. 本節(jié)從機理融合、結構融合和特征融合三個角度介紹CNN與Transformer結合的工作.
1) 機理融合: 該方式通過在Transformer網(wǎng)絡的設計中引入CNN的局部性來提高網(wǎng)絡表達能力. 以Swin Transformer[23]為代表的Transformer網(wǎng)絡通過將注意力限制在局部窗口內, 來顯式地進行局部交互. 此外, CeiT[73]在FFN模塊中, 引入局部特征學習, 以建模局部關系.
2) 結構融合: 這種融合方法通過組合Transformer和CNN的模塊形成新的網(wǎng)絡結構. CeiT[73]和ViTc[35]將卷積模塊添加到Transformer前實現(xiàn)對底層局部信息的提取. MobileViT[75]將Transformer視為卷積層嵌入到卷積神經(jīng)網(wǎng)絡中, 實現(xiàn)了局部信息和全局信息的交互.
3) 特征融合: 該方式在特征級別實現(xiàn)對CNN特征和Transformer特征的融合. 這類方法往往采用并行的分支結構, 并將中間特征進行融合交互. MobileFormer[74]和ConFormer[76]采用并行的CNN和Transformer分支, 并借助橋接實現(xiàn)特征融合. DeiT[58]借助知識蒸餾的思路, 通過引入蒸餾詞符(Distillation token)來將CNN的特征引入到Transformer的學習過程中.
2.2.6 相對位置編碼
原始Transformer使用絕對位置編碼為輸入詞符提供位置信息, 只能隱式地度量相對位置信息[77]. 相對位置編碼 (Relative position encoding, RPE)則直接對序列的距離進行表示, 能夠實現(xiàn)對不同長度的序列的表達不變性, 同時相關關系的顯式度量也有利于提升模型性能[78].



相比NLP任務中輸入為一維詞符序列的語言模型, 視覺任務中輸入為二維圖像, 因此需要二維的位置信息.
SASA中的RPE[81]: 將二維的相對位置信息分為水平和垂直的兩個方向, 在每一個方向進行一維位置編碼, 并與特征嵌入相加, 相對位置信息的計算過程如下所示:

Axial-Deeplab中的RPE[81]: 相比SASA中的RPE只在鍵上加入偏置, 該方法同時對查詢、鍵和值引入了偏置項. 通過軸向注意力, 將二維的注意力先后沿高度和寬度軸分解為兩個一維的注意力.
iRPE (image RPE)[82]: 以往的相對位置編碼都依賴于輸入嵌入, 為了研究位置編碼對輸入嵌入的依賴關系, 該方法提出了兩種相對位置編碼模式, 偏置模式和上下文模式. 偏置模式的相對位置編碼不依賴輸入嵌入, 上下文模式則考慮了相對位置編碼與查詢、鍵和值間的交互. 二者都可以表示為如下形式:


2.3 Transformer的訓練和優(yōu)化問題
Transformer的訓練過程需要精心設計學習率以及權重衰減等多項參數(shù), 并且對優(yōu)化器的選擇也較為苛刻, 例如其在SGD優(yōu)化器上效果較差[35]. 文獻[35]和CeiT[73]在圖像編碼前使用卷積層級來解決Transformer的難優(yōu)化以及參數(shù)敏感的問題, 引入卷積后, 模型對學習率和權重衰減等參數(shù)的敏感性得到了顯著降低, 收斂速度得到加快, 同時在SGD優(yōu)化器上也可以進行穩(wěn)定的學習. 關于在早期引入卷積機制使模型性能得到改善的原因, Raghu等[72]給出了解釋和分析, 他們利用充足的數(shù)據(jù)訓練視覺Transformer, 發(fā)現(xiàn)模型在性能提升的同時, 其在淺層也逐步建立了局部表示. 這表明淺層局部表示對性能提升可能有顯著的影響, 同時也為解釋在淺層引入具備局部關系建模能力的卷積層從而提升Transformer的訓練穩(wěn)定性和收斂速度的現(xiàn)象提供了一個思路.
2.4 結構設計問題
本節(jié)將從整體結構和局部結構兩個角度對Transformer方法以及類Transformer方法進行介紹. 其中, 整體結構上, 我們以圖像特征尺寸變化情況為依據(jù), 將其分為單尺度的直筒型結構和多尺度的金字塔型結構[84]; 在局部結構上, 我們主要圍繞Transformer中基本特征提取單元的結構, 分析卷積以及MLP方法在其中的替代和補充作用以及由此形成的不同局部結構設計.
2.4.1 單尺度和多尺度結構設計
單尺度和多尺度的結構簡圖如圖4所示[84], 其中交互模塊表示空間或通道級的信息交互層, 聚合層表示對全局信息進行聚合, 例如全局最大值池化或基于類別詞符的查詢機制等. 與單尺度結構相比, 多尺度設計的典型特征在于下采樣模塊的引入. ViT[15]是單尺度直筒型結構的代表, 其在網(wǎng)絡不同階段中使用同等長度或尺寸的圖像詞符序列; 與之相對應的是以PVT[22]、Swin Transformer[23]以及CrossFromer[52]等為代表的多尺度金字塔型結構. 多尺度方案可以有效降低網(wǎng)絡參數(shù)和計算量, 從而使得處理高分辨率數(shù)據(jù)成為可能. 文獻[84]對單尺度和多尺度方法進行了對比, 實驗表明多尺度方法相比于單尺度在多種框架中均具備穩(wěn)定的性能優(yōu)勢.
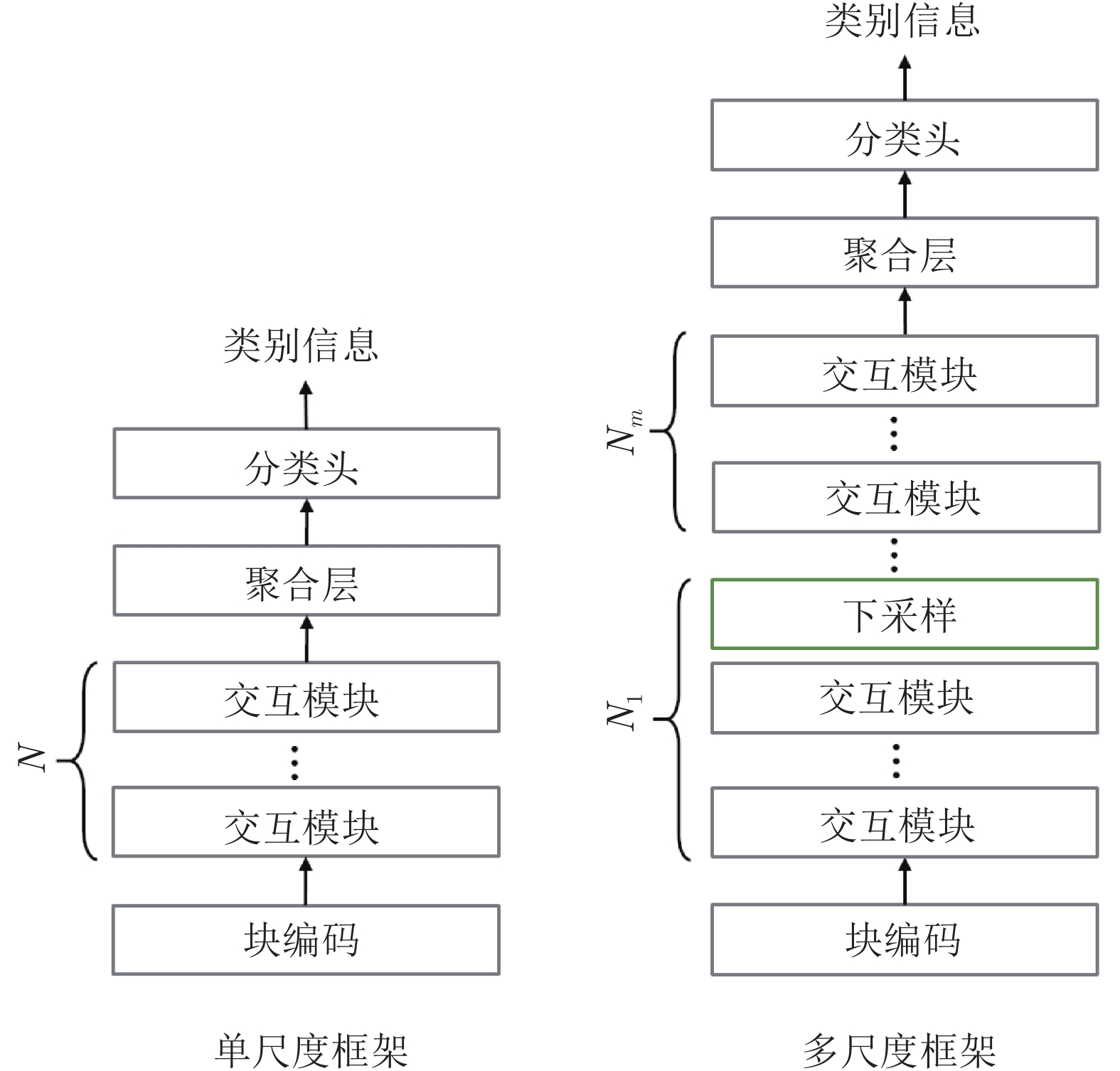
圖 4 單尺度與多尺度結構對比
Fig. 4 The comparison of single-scale framework and multi-scale framework
2.4.2 交互模塊結構設計
如圖1所示, 在ViT[15]的編碼器結構中, 信息交互模塊主要由多頭注意力層和MLP層構成, 其中多頭自注意力層主要完成空間層級的信息交互, 而MLP主要完成通道級別的信息交互[15]. 當前大多數(shù)視覺Transformer的交互模塊設計基本都遵循了這一范式, 并以自注意力機制為核心. 同多頭注意力機制相比, 雖然卷積以及MLP在原理和運行機制上與之存在差異, 但它們同樣具備空間層級信息交互的能力, 因此許多工作通過引入卷積或MLP來替換或增強多頭自注意力機制[34, 85-91], 形成了多樣的交互模塊設計方案. 其中最為典型的是以純MLP架構為代表的無自注意力方案[85-88], 和引入卷積的增強自注意力的方案[34, 91]. 為了簡潔起見, 在本文后續(xù)內容中, 我們將在空間層級進行信息交互的MLP稱為空間MLP機制(Spatial MLP), 將在通道層級進行信息交互的MLP機制稱為通道MLP (Channel MLP). 不同交互模塊的結構如圖5所示.
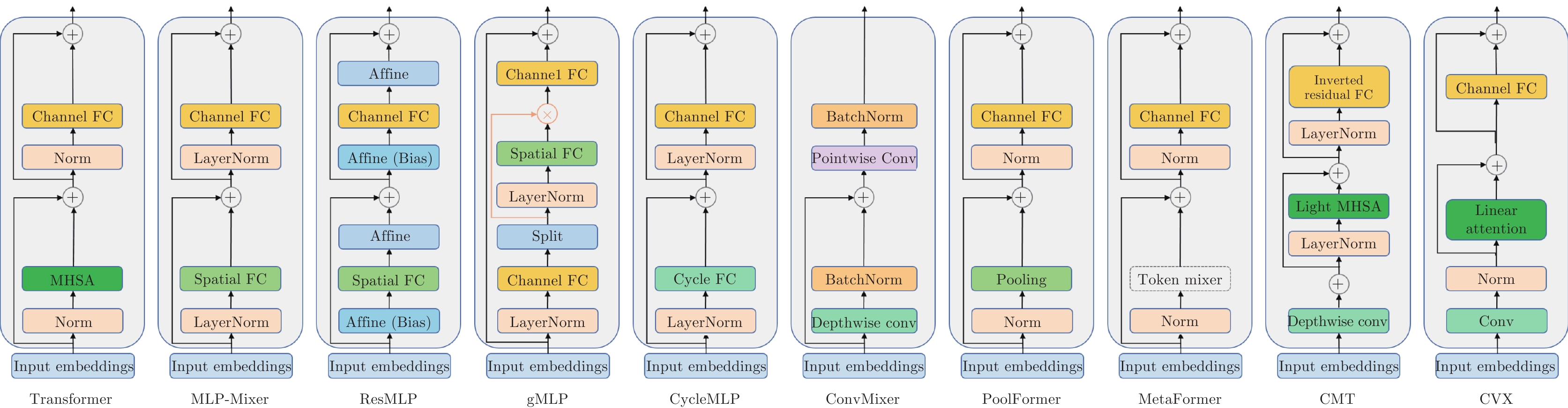
圖 5 類Transformer方法的交互模塊結構對比(Transformer[8], MLP-Mixer[85], ResMLP[86], gMLP[87], CycleMLP[88], ConvMixer[89], PoolFormer[90], MetaFormer[90], CMT[34], CVX[91])
Fig. 5 The comparison of mixing blocks of Transformer-like methods (Transformer[8], MLP-Mixer[85], ResMLP[86], gMLP[87], CycleMLP[88], ConvMixer[89], PoolFormer[90], MetaFormer[90], CMT[34], CVX[91])
1) 無自注意力交互模塊: MLP-Mixer[85]引入了空間MLP來替換多頭自注意力機制, 成為基于純MLP的類Transformer架構的早期代表. 在對圖像塊序列的特征提取中, MLP-Mixer在每一層的開始首先將圖像塊序列轉置, 從而實現(xiàn)利用MLP進行不同詞符之間的交互, 之后經(jīng)過反轉置, 再利用MLP進行通道層級的信息交互. 相比于自注意力機制, MLP的方案實現(xiàn)了類似的詞符間信息聚合功能且同樣具備全局交互能力; 此外, 由于MLP每層的神經(jīng)元的順序固定, 因此其具備位置感知能力, 從而不再需要位置編碼環(huán)節(jié). MLP-Mixer徹底去除了自注意力機制, 僅依靠純MLP組合取得了與ViT相媲美的性能. ResMLP[86]同樣是完全基于MLP的架構, 同時其指出純MLP設計相比于基于自注意力的Transformer方法在訓練穩(wěn)定性上具備優(yōu)勢, 并提出通過使用簡單的仿射變換(Affine transformation)來代替層歸一化等規(guī)范化方法. gMLP[87]提出一種基于空間MLP的門控機制以替代自注意力, 并使用了通道MLP-空間門控MLP-通道MLP的組合構建了交互單元. 為了應對MLP無法處理變長輸入的問題, CycleMLP[88]提出一種基于循環(huán)采樣的MLP機制, 其在類似卷積核的窗口內部, 按照空間順序采樣該位置的某一通道上的元素, 且不同空間位置的采樣元素對應的通道也不同, 從而構建了一種不依賴輸入尺寸的空間交互方法, 同時也具備通道交互能力.
基于卷積也可以實現(xiàn)空間信息交互, 從而同樣具備取代自注意力的可能, ConvMixer[89]使用了逐深度卷積(Depthwise convolution)和逐點卷積(Pointwise convolution)來進行空間和通道信息交互, 從而打造了一個基于純卷積的類Transformer網(wǎng)絡. PoolFormer[90]則使用了更為簡單的Pooling操作來進行空間信息交互, 并進一步提出了更為一般的交互模塊方案MetaFormer[90]. ConNeXt[92]將Swin Transformer[23]網(wǎng)絡的特點遷移到卷積神經(jīng)網(wǎng)絡的設計中, 通過調整不同卷積塊的比例、卷積核大小、激活函數(shù)以及正則化函數(shù)等, 使卷積神經(jīng)網(wǎng)絡的結構盡可能趨近Swin Transformer, 從而在相似計算量下, 實現(xiàn)下超越Swin Transformer的性能. RepLKNet[93]指出在圖像處理中, Transformer的優(yōu)勢可能來源于較大的感受野. 基于這個觀點, RepLKNet通過擴大卷積核, 加入旁路連接和重參數(shù)化機制, 來改造卷積神經(jīng)網(wǎng)絡從而取得了媲美Swin Transformer的效果.
總的來說, 無論是使用MLP還是卷積或者Pooling等具備空間交互能力的算子, 在Transformer的基本框架下, 替換自注意力模塊后依然能夠達到與Transformer類似的性能. 這也表明, 或許自注意力機制并不是Transformer必需的設計, Transformer的性能可能更多來自于整體的架構[90]以及全局交互給感受野帶來的優(yōu)勢[93].
2) 引入卷積的自注意力交互模塊: 卷積所具備的局部空間交互性和通道交互性能夠有效地與自注意力機制形成互補[84], 通過卷積來增強交互模塊的設計在CMT[34]以及CVX[91]等工作中均進行了嘗試并取得了超越基準Transformer的效果. 其中CMT[34]在自注意力前引入卷積增強局部特性建模, 并在通道MLP中加入了卷積增強空間特性建模能力. CVX[91]使用了Performer[54]等線性自注意力機制, 并借助卷積本身的歸納偏置去除了位置編碼和類別詞符.
3. 視覺Transformer的一般性框架
視覺Transformer結構的設計是一個活躍的研究方向, 無論是ViT[15]還是后續(xù)的改進方法, 都很好地拓展了視覺Transformer的設計思路. 但目前仍然缺乏對視覺Transformer通用設計方案的討論. 本節(jié)以底層視覺分類任務為例, 給出視覺Transformer的一般性框架VTA (Vision Transformers architecture), 如圖6所示. VTA給出的視覺Transformer一般性框架包含七層: 輸入層、序列化層、位置編碼層、交互層、采樣層、聚合層以及輸出層. 其中輸入層和輸出層分別完成對輸入的讀取和結果的產(chǎn)生, 下面將對剩余各層進行簡要介紹.
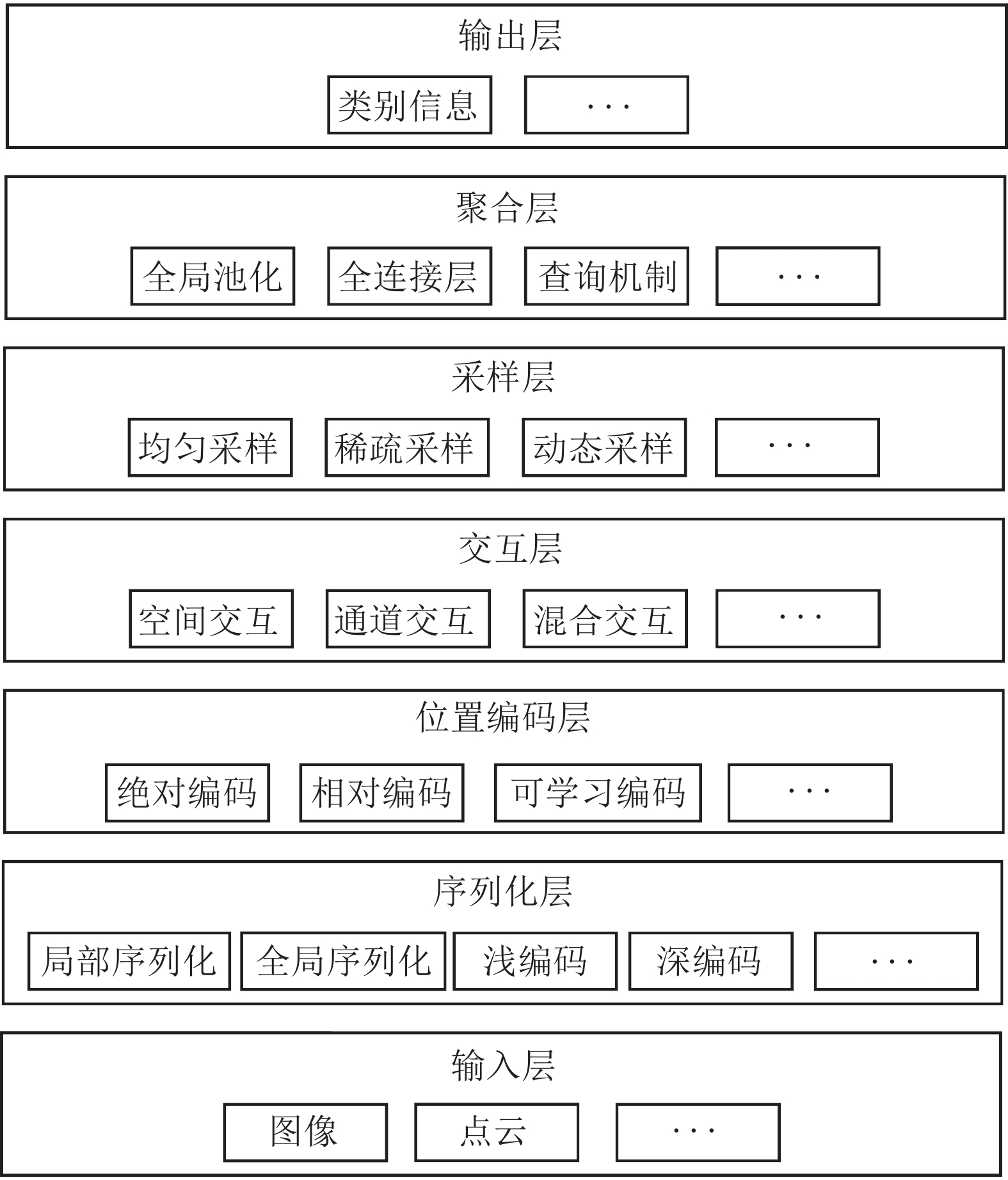
圖 6 視覺Transformer的一般性框架
Fig. 6 Vision Transformers architecture
3.1 序列化層
序列化層的功能在于將輸入劃分為詞符序列的形式, 并進行序列編碼. 其中, 序列劃分方式可以分為局部序列劃分和全局序列劃分. 局部序列劃分將序列分組, 位于同一組的詞符可在后續(xù)環(huán)節(jié)進行交互, 典型的局部序列劃分方法有Swin Transformer[23]所使用的局部窗口機制等. 全局序列劃分則是更一般的序列劃分方法, 這種方式下, 全部詞符均可以進行直接交互. 對編碼方式而言, 主要有淺編碼和深編碼兩種方式, 相對于淺編碼方案, 深度編碼利用更多的卷積層對圖像或劃分后的序列進行處理, 更有利于視覺Transformer的訓練和優(yōu)化[73].
3.2 位置編碼層
對不具備位置感知能力的視覺Transformer方案, 位置編碼層被用來顯式地提取位置信息. 位置編碼方案主要包括絕對位置編碼、相對位置編碼以及可學習位置編碼. 絕對位置編碼僅考慮詞符在序列中的位置信息, 相對位置編碼則考慮詞符對之間的相對位置信息, 更有利于提高模型的表達能力[78]. 此外, 位置編碼還可以可學習的方式進行[16], 以建立更為一般的位置編碼信息.
3.3 交互層
交互層旨在對詞符序列中的特征進行交互, 主要可分為空間交互、通道交互和混合交互模式. 原始的Transformer方案[15]將空間交互和通道交互分離, 并使用基于自注意力機制實現(xiàn)空間交互功能. 其通過計算詞符對之間的相似性來進行加權信息聚合. 基于注意力機制的空間交互是早期Transformer方法的典型特質. 但隨著更多相關工作的開展, 研究人員發(fā)現(xiàn), 自注意力機制也僅是空間交互功能的一種實現(xiàn)方式, 其可以被卷積或空間MLP所替代. 通道信息交互常用的方法是通道MLP. 混合交互機制則打破了空間和通道獨立的限制, 利用包括卷積在內的算子, 同時建立詞符在空間和通道中的關系[73, 89-90].
3.4 采樣層
采樣層旨在對詞符序列進行采樣或合并, 以減少序列中詞符個數(shù), 從而降低計算量. 常見的采樣方式包括均勻采樣、稀疏采樣以及動態(tài)采樣. 其中, 均勻采樣[22]通過池化層或卷積層對相鄰詞符進行合并; 稀疏采樣[24, 52]則在更大的范圍內進行詞符的選擇或合并, 有利于提高感受野范圍. 動態(tài)采樣[51]是一種更為一般性的采樣方案, 其往往通過可學習的過程從輸入的詞符序列中自適應地選擇一些數(shù)量的詞符, 作為后續(xù)網(wǎng)絡的輸入.
3.5 聚合層
對分類任務而言, 聚合層主要完成對詞符特征全局信息的聚合. 全局池化、全連接層是常見的全局信息聚合方式. 這兩種方式都屬于靜態(tài)聚合方案, 其聚合方式不隨輸入內容變化而改變. ViT[15]使用了基于類別詞符的查詢機制, 通過定義可學習和更新的類別詞符變量, 并與輸入詞符序列進行互注意力實現(xiàn)對信息的動態(tài)聚合.
4. 基于Transformer的目標檢測模型
基于卷積神經(jīng)網(wǎng)絡的目標檢測模型訓練流程主要由特征表示, 區(qū)域估計和真值匹配三部分組成:
1) 特征表示: 特征表示基于卷積神經(jīng)網(wǎng)絡來提取輸入的語義特征[5, 94].
2) 區(qū)域估計: 區(qū)域估計通過區(qū)域特征提取算子, 如卷積、裁剪、感興趣區(qū)域池化(RoI pooling)[95]或感興趣區(qū)域對齊(RoI align)[99]等, 獲得局部特征, 并對局部輸入的類別和位置等信息進行估計和優(yōu)化.
3) 真值匹配: 基于卷積神經(jīng)網(wǎng)絡的真值匹配往往通過具備位置先驗的匹配策略, 如重疊度(IoU)、距離等, 進行標注框同錨點框[95, 100]、關鍵點[101]或中心點[102]等參考信息之間的匹配, 建立參考信息的真值, 以此作為網(wǎng)絡學習的監(jiān)督信息.
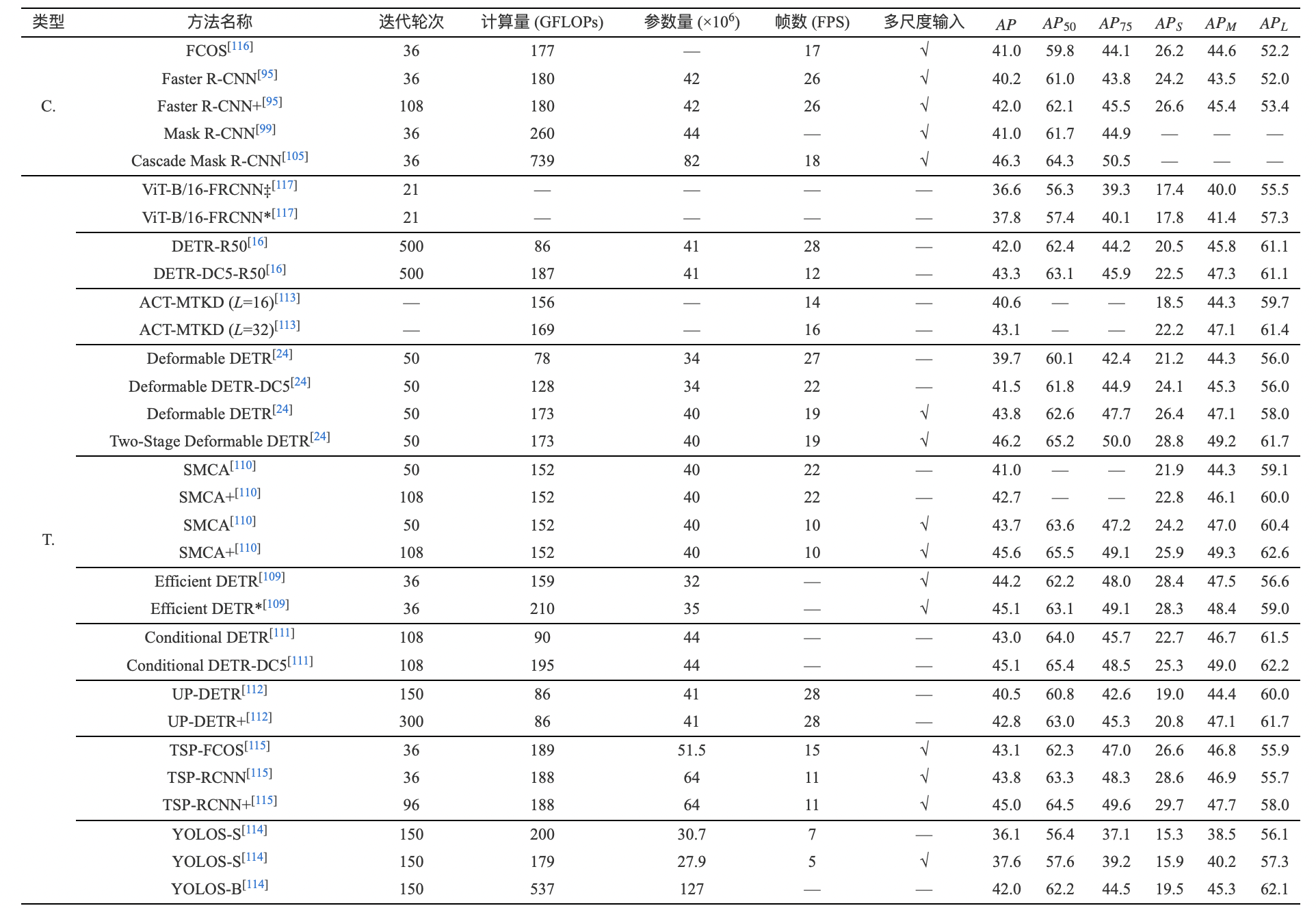
基于Transformer的目標檢測模型拓展了以上三個過程的實現(xiàn)方式. 在特征學習方面, 基于Tranformer的特征構建方式可以取代卷積神經(jīng)網(wǎng)絡的角色[23]; 在區(qū)域估計方面, 基于編碼器?解碼器的區(qū)域估計方式也被大量嘗試和驗證[16]; 在真值匹配方面, DETR[16]提出了基于二分匹配(Bipartite matching)的真值分配方式, 該方法事先不依賴于位置先驗信息, 而是將預測結果產(chǎn)生后將預測值同真實值進行匹配. 本節(jié)將從以上三個角度對基于Transformer的工作進行介紹. 表3總結了不同基于Transformer的目標檢測模型在COCO[103]數(shù)據(jù)集上的性能對比.
表 3 基于Transformer和基于CNN的目標檢測算法在COCO 2017 val數(shù)據(jù)集上的檢測精度比較. 其中C. 表示基于CNN的算法, T. 表示基于Transformer的算法
Table 3 The comparison of detection performance of Transformer-based and CNN-based detectors on COCO 2017 val set. C. denotes CNN-based methods, T. denotes Transformer-based methods
4.1 利用Transformer進行目標檢測網(wǎng)絡的特征學習
作為特征提取器, Transformer網(wǎng)絡具有比CNN更大的感受野和更靈活的表達方式, 因此也有望取得更好的性能以為下游任務提供高質量輸入. 考慮到特征學習屬于Transformer網(wǎng)絡的基礎功能,并已在第 2 節(jié)中進行了詳細梳理, 因此本節(jié)將簡要介紹其設計, 而更多地關注此類方法在目標檢測器中的應用.
基于層級結構設計的PVT[22]、基于卷積和Transformer融合的CMT[34]、基于局部?整體交互的Cross Former[52]、Conformer[76]以及基于局部窗口設計的Swin Transformer[23]均被成功應用到了RetinaNet[104]、Mask R-CNN[99]、Cascade R-CNN[105]、ATSS[106]、RepPoints-v2[107]和Sparse RCNN[108]等典型目標檢測網(wǎng)絡中, 相比于ResNet等卷積神經(jīng)網(wǎng)絡取得了更好的效果. 這類方法基于典型的目標檢測流程, 將Transformer作為一種新的特征學習器, 替代原有的卷積神經(jīng)網(wǎng)絡骨架, 從而完成目標檢測任務.
4.2 利用Transformer進行目標信息估計
不同于CNN利用卷積實現(xiàn)對區(qū)域信息的估計和預測, 基于Transformer的目標檢測網(wǎng)絡使用了查詢機制, 通過查詢與特征圖的注意力交互實現(xiàn)對目標位置、類別等信息的估計. 本小節(jié)將以DETR[16]中的目標查詢機制為例介紹查詢機制的作用, 并總結目前存在的問題以及解決方案. DETR的基本結構如圖7所示.
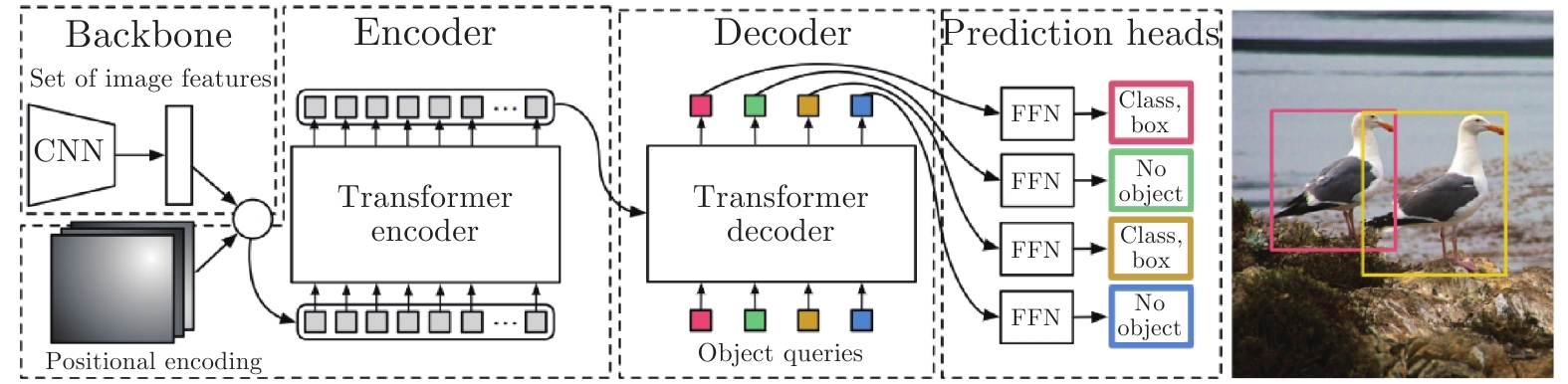
圖 7 DETR的結構圖[16]
Fig. 7 The framework of DETR[16]
4.2.1 DETR中的目標查詢機制
DETR[16]首先通過編碼器提取圖像特征, 之后利用隨機初始化的目標查詢機制來與圖像特征進行交互, 以互注意力的機制進行目標級別信息的提取, 經(jīng)過多層交互之后, 利用全連接層從每個目標查詢中預測目標的信息, 形成檢測結果.
目標查詢向量包含了潛在目標的位置信息和特征信息, 其與圖像特征進行交互的過程實現(xiàn)了從全局信息中對潛在目標特征的抽取, 同時完成了對預測位置的更新. 多個查詢層的堆疊構建了一種類似Cascade RCNN[105]的迭代網(wǎng)絡[109], 以更新目標查詢的方式實現(xiàn)對位置和特征信息的優(yōu)化. 為了清楚地介紹Transformer的設計機制, 本文將目標查詢所表示的內容分成兩部分, 一部分是與特征內容有關的, 記為內容嵌入(Content embedding), 一部分是與位置有關的, 記作位置嵌入(Positional embedding).
這種目標查詢的方式實現(xiàn)了較為有效的目標檢測功能, 但同時存在著收斂速度較慢[24, 110-111] (DETR需要500個輪次的訓練才能收斂)、小目標檢測效果不佳[24]以及查詢存在冗余[113]等問題. 其中, 針對小目標檢測效果差的問題, 現(xiàn)有文獻的主要做法是利用多尺度特征[24], 通過在不同分辨率特征圖上進行目標查詢, 增加對小目標物體的信息表示, 以提高小目標的準確率. 針對目標查詢存在冗余的現(xiàn)象, ACT[113]提出使用局部性敏感哈希(Locality sensitivity hashing, LSH)算法實現(xiàn)自適應聚類, 以壓縮目標查詢的個數(shù), 從而實現(xiàn)更為高效的目標查詢. 本小節(jié)將主要針對以DETR[16]為代表的網(wǎng)絡收斂速度慢的問題, 分析其原因并總結提升訓練速度的方案.
4.2.2 收斂速度提升
圖8展示了DETR[16]以及其改進方法與基于CNN的檢測器的收斂速度對比, 可以看到DETR需要長達500個輪次的訓練才能得到較為穩(wěn)定的效果. 其收斂較慢的主要原因在于目標查詢機制的設計[24, 110-111], 本節(jié)從查詢初始化、參考點估計和目標分布三個方面分析DETR的設計并總結了提升收斂速度的方法.
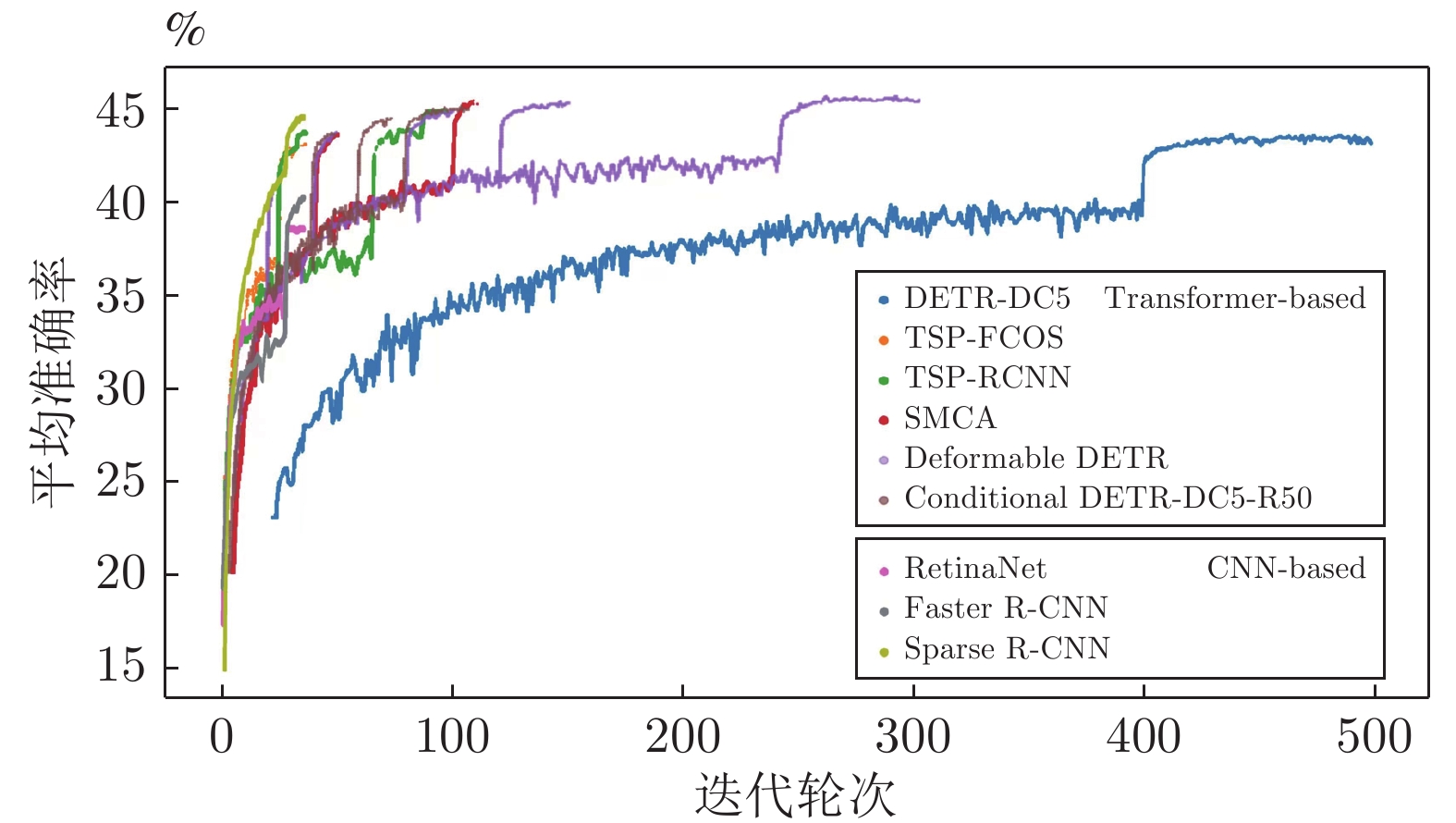
圖 8 基于Transformer和CNN的目標檢測器的收斂速度對比(DETR-DC5[16], TSP-FCOS[115], TSP-RCNN[115], SMCA[110], Deformable DETR[24], Conditional DETR-DC5-R50[111], RetinaNet[104], Faster R-CNN[95], Sparse R-CNN[108])
Fig. 8 The comparison of converge speed among object detectors based on Transformer and CNN (DETR-DC5[16], TSP-FCOS[115], TSP-RCNN[115], SMCA[110], Deformable DETR[24], Conditional DETR-DC5-R50[111], RetinaNet[104], Faster R-CNN[95], Sparse R-CNN[108])
1) 輸入依賴的目標查詢初始化: DETR[16]對目標查詢使用了隨機初始化的方法, 通過訓練時的梯度更新來實現(xiàn)對目標查詢輸入的優(yōu)化, 以學習輸入數(shù)據(jù)集中的物體的統(tǒng)計分布規(guī)律. 這種方式需要較長的過程才能實現(xiàn)對物體位置分布的學習, 其可視化表現(xiàn)為交叉注意圖(Cross-attention map)的稀疏程度需要較長的訓練輪次才能收斂[115] (如圖9所示). 此外, 關于目標分布的統(tǒng)計信息屬于一種數(shù)據(jù)集層面的特征, 無法實現(xiàn)對具體輸入的針對性初始化, 也影響了模型的收斂速度.
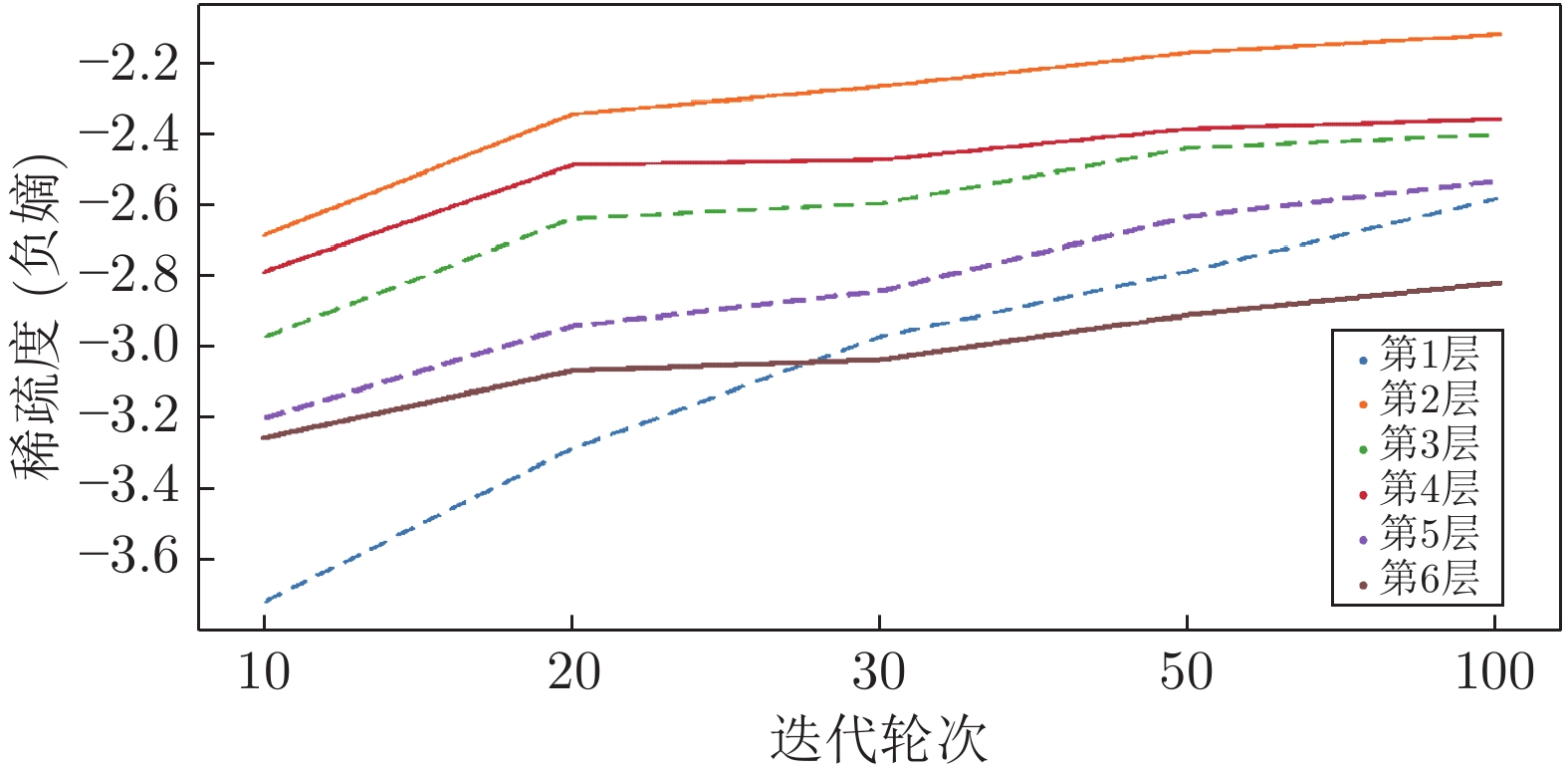
圖 9 DETR交叉注意力稀疏性變化
Fig. 9 The change of sparsity of cross-attention map in DETR
為了改善由于初始化而造成的收斂速度慢的問題, TSP[115]和Efficient DETR[109]等工作提出了輸入依賴的查詢初始化方法, 從輸入圖像特征中預測潛在目標的位置和尺寸等信息, 作為初始的目標查詢輸入到編碼器或解碼器網(wǎng)絡, 進而得到最終的目標檢測結果. 其中, TSP[115]使用了CNN網(wǎng)絡作為產(chǎn)生初始目標查詢的途徑, 借鑒FCOS[116]和RCNN[118]的思路, 分別提出了TSP-FCOS和TSP-RCNN進行圖像中目標信息的估計, 并借助Transformer編碼器實現(xiàn)對目標估計的優(yōu)化; Efficient DETR[109]使用基于Transformer的編碼器網(wǎng)絡學習到的詞符特征進行密集預測, 得到相應位置可能的目標的位置、尺寸和類別信息, 并選擇置信度較高的結果作為目標查詢的初始狀態(tài), 然后利用解碼器進行稀疏預測, 得到最終結果.
TSP[115]和Efficient DETR[109]所提出的目標查詢初始化方法一方面夠根據(jù)不同輸入得到不同的目標查詢初始化結果, 是一種輸入依賴的初始化方式; 另一方面, 實現(xiàn)了目標查詢所包含的內容嵌入和位置嵌入的顯式對齊, 從而較好地加速了目標檢測器的收斂.
2) 輸入依賴的位置嵌入更新: DETR位置嵌入的弱定位能力也是影響DETR模型收斂的主要原因之一. 在DETR[16]解碼器中的多層網(wǎng)絡中, 目標查詢的內容嵌入通過交叉注意力實現(xiàn)對自身信息的更新, 但位置嵌入并不在層之間進行更新. 這種方式一方面導致了位置嵌入與內容嵌入的不匹配, 另一方面還導致位置嵌入難以準確表達潛在目標的準確位置信息, 使得獲取位置信息的任務轉移到內容嵌入中[111]. Conditional DETR[111]通過對比實驗發(fā)現(xiàn), 去掉解碼器中第2層之后的位置嵌入信息, DETR的平均準確率僅下降0.9%, 從而說明了在原始的DETR的解碼器中的位置嵌入所發(fā)揮的作用很小.
Deformable DETR[24]、SMCA[110]和Conditional DETR[111]等方法從每層輸入信息中學習位置嵌入信息的更新, 能夠較好地彌補DETR設計中位置嵌入定位能力不足的缺陷. 其中, Deformable DETR[24]和SMCA[110]從目標查詢中預測了每個查詢對應的參考點坐標, 來提高定位能力; Conditional DETR[111]利用目標查詢預測二維坐標信息, 并利用內容嵌入學習對坐標嵌入信息的變換, 使位置嵌入和內容嵌入在統(tǒng)一空間, 進而使得目標查詢和鍵值在統(tǒng)一空間, 從而提高相似性判別和定位能力.
3) 顯式目標分布建模: DETR[16]使用了信息相似性度量來實現(xiàn)在全局范圍內的目標嵌入的信息聚合, 這種方式有助于更完全地獲取目標的信息, 但同時也可能引入較多的噪聲干擾[24], 從而影響學習過程, 而且, 從全局信息中收斂到潛在目標的局部空間也需要較長的訓練過程.
建立對潛在目標分布空間的建模機制有助于加速目標檢測過程, 減少訓練時間, 同時減少噪聲的引入[24, 110]. 矩形分布假設是基于CNN的目標檢測器的常用設計之一[95, 100], 在基于Transformer的目標檢測器中, 雖然圖片以序列的方式進行編碼和解碼, 但仍可以借助逆序列化獲取二維的圖片結構的數(shù)據(jù). 并在此基礎上,實現(xiàn)類似CNN網(wǎng)絡中的感興趣區(qū)域池化等操作, 以此實現(xiàn)對目標空間的建模. 現(xiàn)有對Transformer目標分布進行顯式建模的方法主要有兩種: 散點分布[24]和高斯分布[110].
散點分布: Deformable DETR[24]利用了散點采樣實現(xiàn)對目標空間分布的建模. 針對每一個目標查詢, Deformable DETR首先從中學習目標的參考點坐標、采樣點坐標和采樣點權重, 然后在若干采樣點之間計算局部范圍內的注意力, 并進行信息聚合. 這種方式大大減少了計算量, 同時可以較靈活地模擬目標的空間分布, 實現(xiàn)對于與目標查詢有關聯(lián)的點的聚合, 從而加速了網(wǎng)絡的收斂過程.
高斯分布: SMCA[110]提出了一種利用高斯函數(shù)建模目標空間分布, 實現(xiàn)局部信息聚合的方法. SMCA首先從目標查詢中學習潛在目標的位置和尺寸信息, 之后, 根據(jù)預測得到的位置和物體尺寸信息建立二維高斯分布函數(shù), 來對近距離特征賦予較高權重, 對遠距離特征賦予較低權重.
4.3 基于Transformer的目標檢測模型的真值匹配

不同于CNN中基于錨點框或關鍵點的真值匹配方式, 二分匹配是在得到預測結果后進行, 基本上是一種不確定性策略, 且容易受到訓練過程的干擾[115], 進而導致訓練過程(尤其是訓練過程的早期)收斂速度較慢. 針對這個問題TSP[115]基于FCOS提出了一種新的匹配策略, 僅將落在真實標注框內的預測值或與標注框有一定重合的預測值與該真實值進行匹配, 從而加速收斂速度.
5. 基于Transformer的圖像分割模型
圖像分割主要包括語義分割, 實例分割和全景分割[119], 近些年, 以FCN[120]、DeepLab[45]、Mask RCNN[99]等方法為代表的圖像分割方法已經(jīng)取得了較好的效果, 但這種基于卷積神經(jīng)網(wǎng)絡的圖像分割方法在建立遠程依賴上依舊存在不足. 相比之下, Transformer網(wǎng)絡所具備的全局信息交互能力能夠幫助特征提取器快速建立全局感受野, 從而實現(xiàn)更準確的場景理解[121]. 表4、表5和表6分別展示了基于Transformer的語義分割、實例分割和全景分割方法的結果以及其與經(jīng)典CNN方法的對比. 本節(jié)將主要從特征提取、分割結果生成兩個方面介紹Transformer在圖像分割中的應用.
表 4 基于Transformer的語義分割算法在ADE20K val數(shù)據(jù)集上的語義分割精度比較. 其中, 1k表示ImageNet-1k, 22k表示ImageNet-1k和ImageNet-21k的結合
Table 4 The comparison of semantic segmentation performance of Transformer-based methods on ADE20K val set. 1k denotes ImageNet-1k dataset, 22k denotes the combination of ImageNet-1k and ImageNet-21k

表 5 基于Transformer的實例分割方法和基于CNN算法在COCO test-dev數(shù)據(jù)集上的實例分割精度比較
Table 5 The comparison of instance segmentation performance of Transformer-based and typical CNN-based methods on COCO test-dev dataset
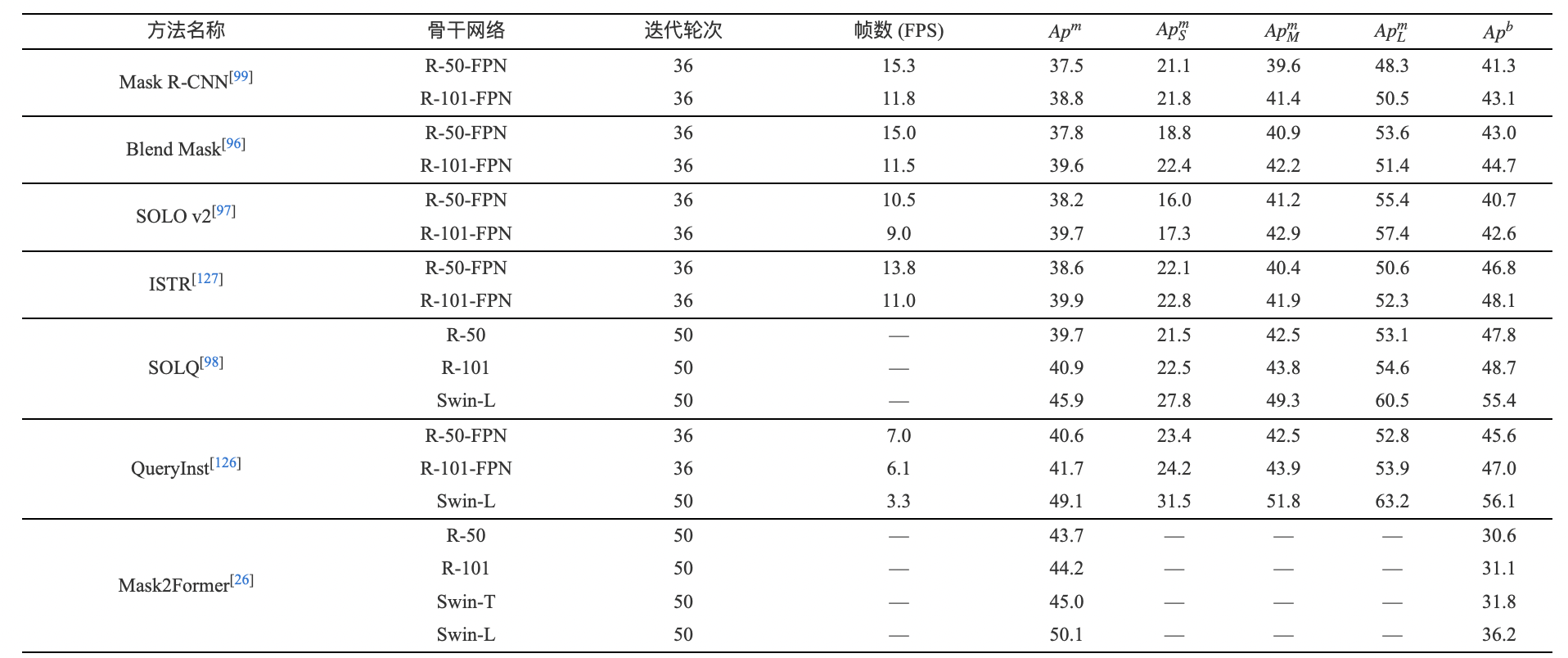
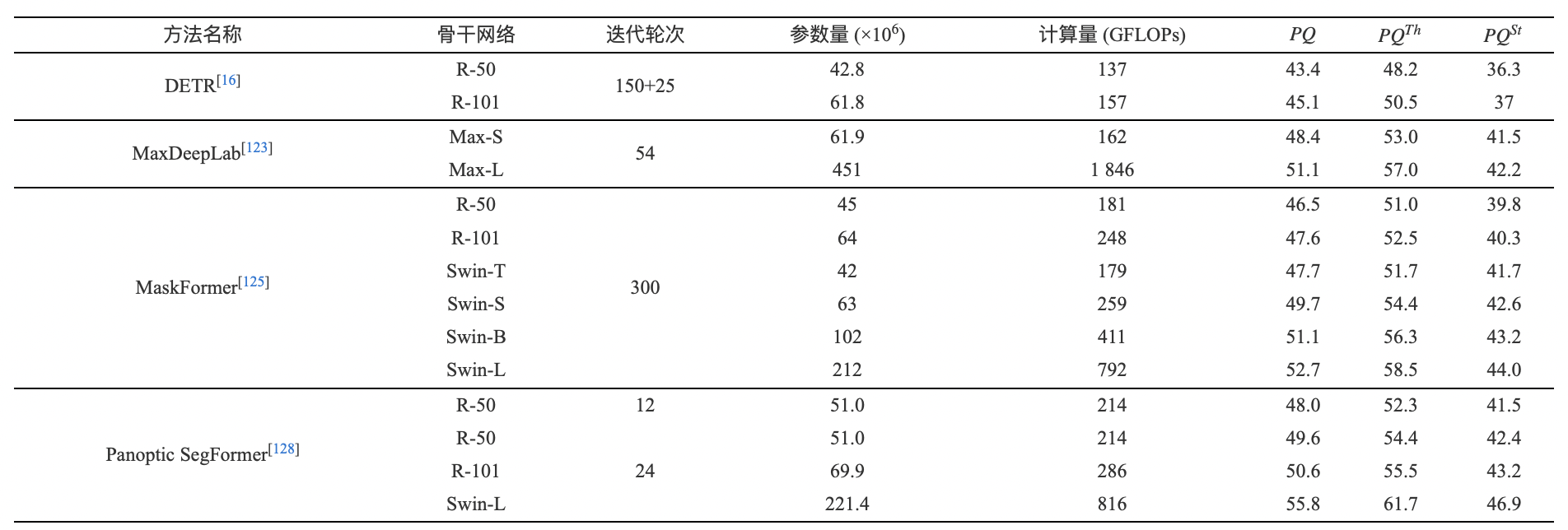
表 6 基于Transformer的全景分割算法在COCO panoptic minval數(shù)據(jù)集上的全景分割精度比較
Table 6 The comparison of panoptic segmentation performance of Transformer-based methods on COCO panoptic minival dataset
5.1 基于Transformer進行分割網(wǎng)絡的特征學習
Transformer網(wǎng)絡以一定尺寸的圖像塊作為最小特征單元, 其編碼后的特征經(jīng)過上采樣操作就可以集成到現(xiàn)有的圖像分割框架中. Transformer以其全局感受野和動態(tài)交互能力, 使得圖像分割模型能夠對圖像中的上下文關系進行充分表示和建模, 從而取得更好的效果[22-23, 34, 52-53, 72, 76].
除了將Transformer集成到現(xiàn)有分割框架以替換CNN之外, 近期的一些工作還針對Transformer設計了新的分割框架以充分利用其在有效感受野等方面的優(yōu)勢[25, 121]. 其中, SETR[121]以序列學習的視角提出了基于ViT[15]的完全由自注意力機制構成的特征編碼網(wǎng)絡, 并在此基礎上提出了三種解碼方案(簡單上采樣解碼器、漸進式解碼器和多尺度融合解碼器)產(chǎn)生分割結果, 打破了語義分割任務基于編碼器?解碼器的FCN范式, 其結構如圖10所示. SegFormer[25]針對SETR柱狀編碼方式計算量較大以及固定位置編碼不利于拓展等問題, 提出了使用具備層次結構的Transformer網(wǎng)絡以保留粗粒度和細粒度兩種特征, 并通過在自注意力中引入卷積機制來去除位置編碼提高了網(wǎng)絡靈活性. SegFormer同時指出, 基于Transformer的圖像分割網(wǎng)絡可以在僅使用較為簡單的解碼器的情況下,實現(xiàn)不錯的效果, 并提出了一種僅包含數(shù)個線性層的解碼器方案.
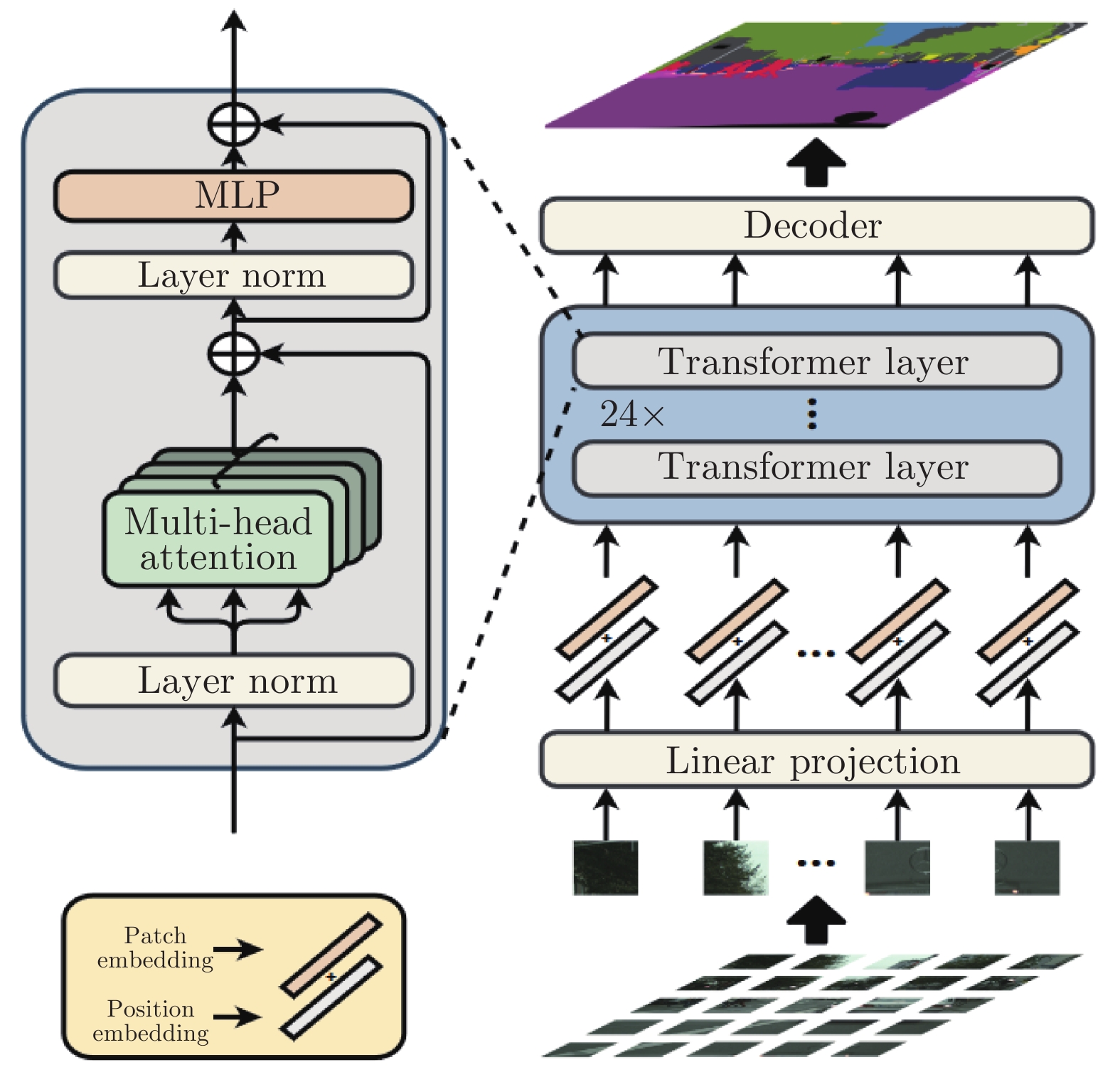
圖 10 SETR的結構圖[121]
Fig. 10 The framework of SETR[121]
5.2 利用Transformer產(chǎn)生圖像分割結果
像素分割和實例分割是圖像分割中的兩個基本任務, 在基于卷積神經(jīng)網(wǎng)絡的方法中, 前者往往基于解碼器?編碼器的結構產(chǎn)生, 后者則通常借助RCNN實現(xiàn)對目標級別信息的輸出[119]. Transformer的出現(xiàn), 尤其是其目標查詢機制, 為解決圖像分割提供了一種新的思路, 而且有望以一種統(tǒng)一的方式實現(xiàn)像素和實例級別的分割. Transformer的查詢機制可以用來表示多種信息, 既可以表示類別信息[124]、位置信息[26, 125]同時也可以表示其他特征信息[126], 這種具備通用性的表示形式為實現(xiàn)統(tǒng)一形式的圖像分割提供了基礎. 本節(jié)將主要從基于目標查詢的語義分割和實例分割兩方面介紹Transformer給圖像分割領域帶來的啟發(fā)和改變, 并結合全景分割, 總結以統(tǒng)一的方式進行圖像分割的工作.
5.2.1 基于查詢的語義分割方法
按照產(chǎn)生結果的形式, 基于查詢的語義分割方法可以分為像素級預測[124]和掩碼級預測[125], 前者為每一個像素輸出一個類別信息, 后者則對掩碼內的像素統(tǒng)一預測一個類別信息. 在語義分割任務中, 查詢以隨機初始化的方式產(chǎn)生, 之后通過與圖像特征的交互實現(xiàn)對類別信息的提取, 并最終用于產(chǎn)生分割結果.
1) 像素級語義分割: Segmenter[124]利用類別嵌入(Class embedding)建立目標查詢, 通過交叉注意力與圖像序列進行信息交互, 最終利用類別嵌入與圖像序列之間的注意力圖進行圖像塊的逐像素分割結果預測.
2) 掩碼級語義分割: MaskFormer[125]借鑒了DETR[16]中的集合預測思想, 提出了掩碼級的語義分割思路, 其使用了Transformer和CNN兩種解碼器, 其中Transformer解碼器基于隨機初始化的查詢實現(xiàn)對類別信息的預測, CNN解碼器則通過常規(guī)卷積實現(xiàn)對二進制掩碼信息的預測, 最后通過融合類別預測和掩碼預測得到語義分割結果. 這種掩碼級的語義分割結果生成方式一方面簡化了語義分割任務, 另一方面能夠與實例分割實現(xiàn)較好的統(tǒng)一. 在性能上, MaskFormer也驗證了在類別數(shù)目較多的情況下, 基于掩碼的語義分割相比于像素級分割方式在性能上更具優(yōu)勢.
Mask2Former[26]進一步提升了掩碼級語義分割的性能和訓練速度, 其基于MaskFormer[125]提出了利用多尺度特征來增強對小目標的分割能力, 同時使用了掩碼注意力來關注目標局部信息, 從而加速Transformer網(wǎng)絡的收斂速度.
5.2.2 基于目標查詢的實例分割和全景分割方法
在基于Transformer的語義分割方法中[26, 125], 查詢通常與類別信息相關, 而在實例分割中, 查詢則往往與前景目標的位置和特征相關[126-128], 這與基于Transformer的目標檢測網(wǎng)絡中的查詢機制所表示的信息基本一致[16]. 根據(jù)目標信息預測和掩碼生成的順序, 本小節(jié)將基于目標查詢的實例/全景分割方法分為基于檢測的分割方法和檢測分割并行的方法.
1) 基于檢測的實例/全景分割方法: DETR[16]在目標檢測結果的基礎上生成檢測框嵌入, 通過與圖像編碼特征進行交互提取目標特征, 之后基于查詢與圖像特征的注意力圖進行目標和背景掩碼的預測. 不同于DETR[16]中將目標和背景均表示為檢測框的方式, Panoptic SegFormer[128]提出區(qū)分前景目標和背景信息更有利于產(chǎn)生準確的背景預測. 在解碼階段, Panoptic SegFormer首先使用位置解碼器針對前景目標提取目標信息, 在此基礎上引入背景查詢, 并利用掩碼解碼器產(chǎn)生掩碼結果.
2) 檢測分割并行的實例分割方法: 基于Sparse RCNN[108], QueryInst[126]和ISTR[127]提出了檢測分割并行的實例分割方法. 其中, QueryInst[126]基于隨機初始化的目標位置從圖像中獲取區(qū)域信息, 同時以隨機初始化的方式生成目標特征信息, 之后通過不斷地迭代, 優(yōu)化查詢的學習以及對目標的信息提取. 目標特征信息用于學習動態(tài)卷積的參數(shù)以實現(xiàn)對區(qū)域特征的動態(tài)處理, 在此基礎上并行產(chǎn)生包圍框和掩碼預測. ISTR[127]同樣采用了隨機初始化的查詢來表示目標的包圍框信息, 但采用了圖像特征作為產(chǎn)生動態(tài)卷積參數(shù)的輸入. QueryInst[126]和ISTR[127]這種基于查詢的迭代式預測方式降低了對目標包圍框預測的要求, 使得隨機初始化的目標信息依然能夠在幾輪迭代之后建立對目標的準確描述.
6. 總結與展望
本文介紹了視覺Transformer模型基本原理和結構, 以圖像分類為切入點總結了Transformer作為骨干網(wǎng)絡的關鍵研究問題和最新進展, 并提出了視覺Transformer的一般性框架, 同時以目標檢測和圖像分割為例介紹了視覺Transformer模型在上層視覺任務中的應用情況. 視覺Transformer網(wǎng)絡作為一種新的視覺特征學習網(wǎng)絡, 在連接范圍、權重動態(tài)性以及位置表示能力等方面與CNN網(wǎng)絡有著較大的差異. 其遠距離建模能力和動態(tài)的響應特質使之具備了更為強大的特征學習能力, 但同時也帶來了嚴重的數(shù)據(jù)依賴和算力資源依賴等問題. 對視覺Transformer的效率和能力的研究仍將是未來的主要研究方向之一, 此外, Transformer模型為多模態(tài)數(shù)據(jù)特征學習和多任務處理提供了一種統(tǒng)一的解決思路, 基于Transformer的視覺模型有望實現(xiàn)更好的信息融合和任務融合.
參考文獻:







![]()


來源:王飛躍科學網(wǎng)博客